Resource Schema Handling
Introduction
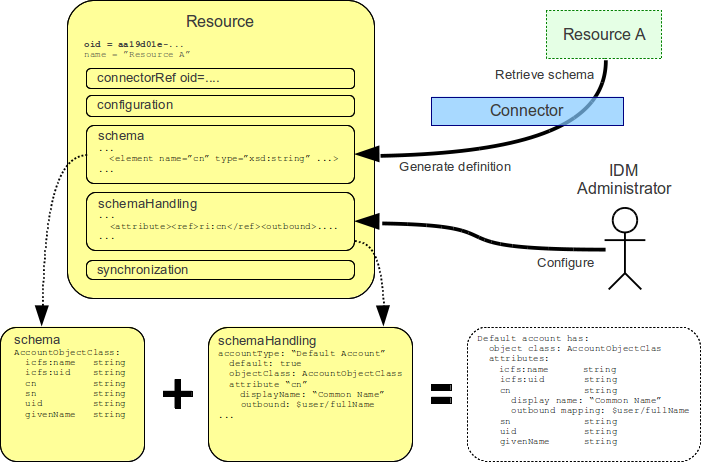
Resource schema handling is a definition of how the Resource Schema is used by midPoint. Simply speaking, the resource schema handling defines how the individual attributes should be named, whether they are readable or writeable, how to fill the values of such attributes if new account is being created, how to use the attributes if a change is detected on the resource, etc.
The resource schema handling is related to the Resource Schema, but there is a fundamental distinction:
-
Resource Schema specifies capabilities of the resource and the connector. It does not define how the schema is used (although it may suggest it).
-
Resource schema handling specifies the decisions of IDM administrators. It defines how the resource schema is used by midPoint to implement parts of IDM logic, present the data to the user, etc.
While Resource Schema is usually generated from the resource by a connector, the resource schema handling must be defined by the IDM administrator. Defining resource schema handling is a substantial part of midPoint customization.
Schema handling defines object types (accounts, entitlements, other types of objects) and types of associations among them. Accounts are data records representing users on the Resource. Entitlements are objects that can be assigned to accounts (such as groups, roles, privileges, team membership, etc.). See Basic Data Model for the introduction to these concepts.
Resource Object Types
By resource object we understand any object on the resource that is visible to midPoint. These are usually account objects but may also be a wide variety of group types, resource-specific low-level roles, privileges, organizational units, configuration objects, etc. Strictly speaking resource objects are the objects stored on the resource. When they are replicated to midPoint we call them resource object shadows (or just shadows). These two terms are often used interchangeably.
It is critical for a successful IDM deployment to correctly understand the meaning and usage patterns of resource objects for each resource connected to midPoint. Identity management is mostly just after manipulating resource objects after all. Therefore it is vital to configure midPoint to correctly understand and handle individual resource object types. Therefore the major part of the schema handling section is dedicated to this task. The configuration may seem to be a bit complex at the first sight. But it is very flexible and powerful. Having this part of the configuration right significantly simplifies the overall IDM solution.
For the definition of object types, see Resource Object Types.
Association Types
Besides object types, we can define associations between them.
See Entitlements and Associations for more information.
Object Classes
There may be situations when you want to override some settings (for example, attribute values cardinality, protected objects, or attribute fetch strategy) not only for selected object type(s), but for all objects in a given object class.
For example, you may need to specify fetch strategy for specific attribute of groupOfUniqueNames object class, and apply this consistently to all object types defined for this object class.
To do so, special schemaHandling/objectClass definition can be used.
See Also
External links
-
Evolveum - Team of IAM professionals who developed midPoint
Was this page helpful?
YES
NO
Thanks for your feedback