System Performance Testing (TestSystemPerformance)
This is a description of TestSystemPerformance, a tool used to measure the performance of midPoint in an artificial environment of zero-delay resources.
The goal is to measure the performance of midPoint as such. In particular, we use it to determine the effects of changes. When new features are added, they often decrease the performance, like when adding role membership or value metadata. On the other hand, we regularly try to improve the performance by optimizing the processing within midPoint. This test is aimed to quantify the effects of both kinds of changes.
TestSystemPerformance is a class that generates a specific system configuration, based on a number of parameters.
Then it runs a set of tasks that measure the time needed to execute import, reconciliation, and recomputation tasks.
It provides overall performance numbers for these tasks, along with detailed internal metrics that can be used to evaluate the performance of individual midPoint components.
It is run regularly via jenkins jobs (see TODO here). However, it can be run directly on any machine, as described in How to Run section below.
Testing Scenario Overview
Source and Target Resources
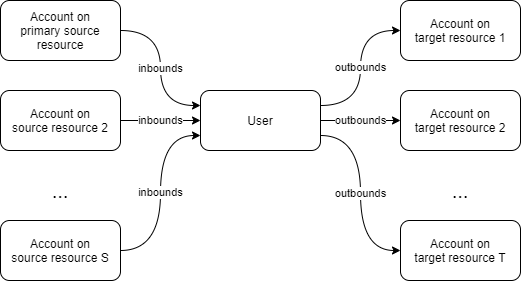
There is a set of S source and T target resources. Each identity (midPoint user) has one account
on each source and one account on each target resource. The number of resources is configurable:
S ≥ 1, T ≥ 0.
Data Structures and Mappings
One of goals of this scenario is to test the performance of mapping evaluation. Therefore, we evaluate
a set of SMsingle ≥ 0 mappings of dummy single-valued attributes/properties, and a set of SMmulti ≥ 0
mappings of dummy multi-valued attributes/properties, each of which has V ≥ 1 distinct values for each account.
(SM stands for source mapping here. If SMsingle = SMmulti, we can simply speak of SM.)
In order to avoid values being overwritten, single-valued mappings are present only on the first source resource. We call it the primary source. Multi-valued properties are evaluated separately per resource: each value is prefixed by the identifier of the resource on which it originates, and the mapping has an appropriate range defined. See below.
Similarly, target (outbound) mappings are defined as well. We can define their number using TMsingle, TMmulti
(or simply TM) parameters. Note that unlike single-valued inbound mappings, which are present only on
primary source resource, both single- and multi-valued outbound mappings are present equally on all
target resources.
The following picture shows a situation with two sources (S = 2), single target (T = 1), 100 single-valued
inbound mappings (on primary source) and 100 multi-valued outbound mappings (on both sources), and 100 + 100
mappings on the target resource (SM = TM = 100).
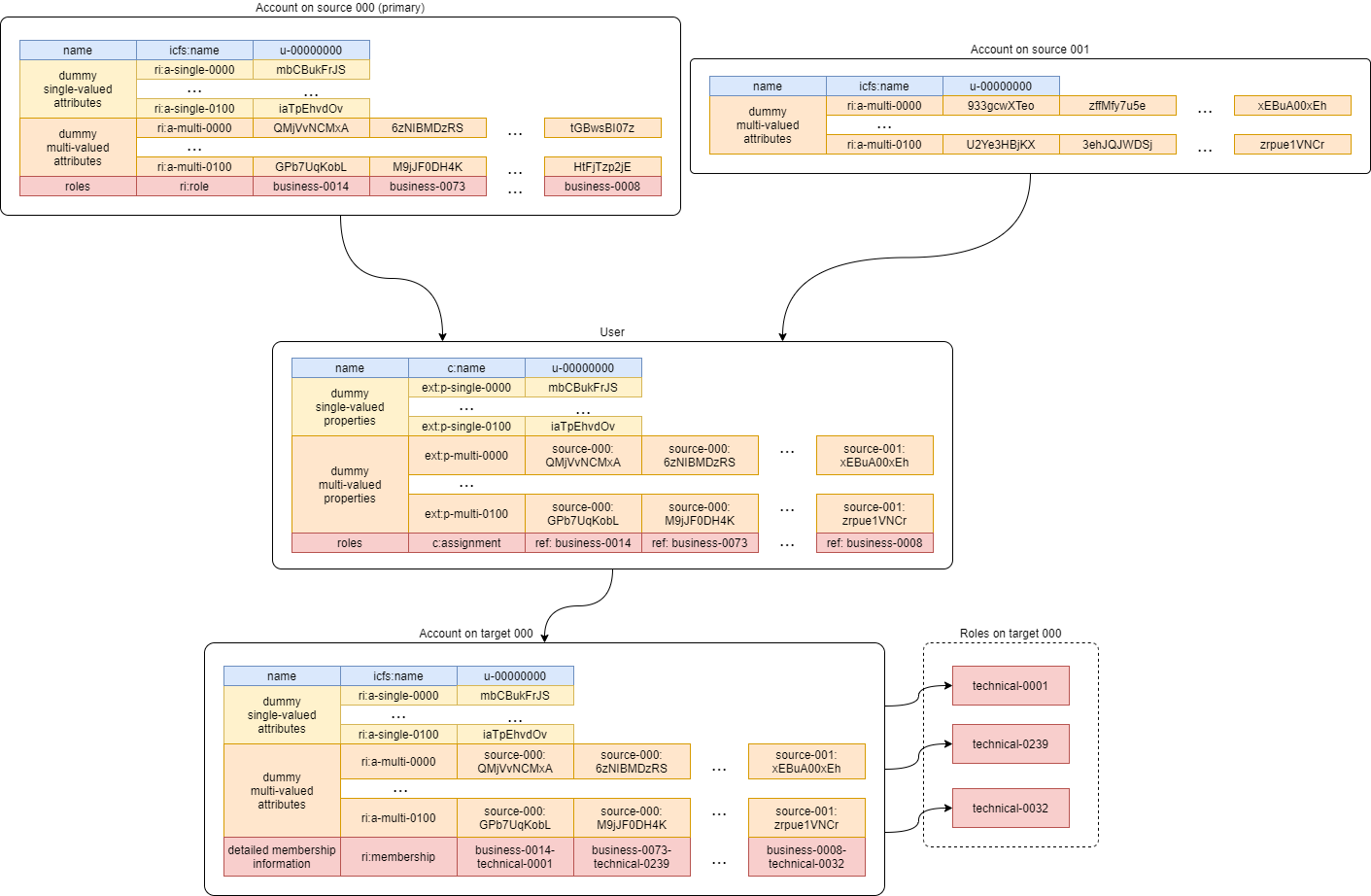
Note that besides dummy attributes/properties there are some other ones: obvious name, and custom
roles and membership. They will be described later.
For simplicity, the accounts (users) names are unified. They are in the form of u-00000001.
The number of accounts on each resource is driven by parameter U ≥ 1.
The dummy mappings look like this:
Inbound single-valued:
<attribute>
<ref>ri:a-single-0000</ref>
<inbound>
<expression>
<script>
<code>input</code>
</script>
</expression>
<target>
<path>extension/p-single-0000</path>
</target>
</inbound>
</attribute>
Inbound multi-valued:
<attribute>
<ref>ri:a-multi-0047</ref>
<inbound>
<expression>
<script>
<code>'source-000:' + input</code>
</script>
</expression>
<target>
<path>extension/p-multi-0047</path>
<set>
<condition>
<script>
<code>input.startsWith('source-000:')</code>
</script>
</condition>
</set>
</target>
</inbound>
</attribute>
Outbound mappings are similar. For example, multi-valued ones are like this:
<attribute>
<ref>ri:a-multi-0000</ref>
<outbound>
<source>
<name>data</name>
<path>extension/p-multi-0000</path>
</source>
<expression>
<script>
<code>data</code>
</script>
</expression>
</outbound>
</attribute>
Extension Schema
As seen above, the extension schema contains definitions for p-single-xxxx and p-multi-xxxx properties.
These can be indexed or not, depending on the configuration.
Roles
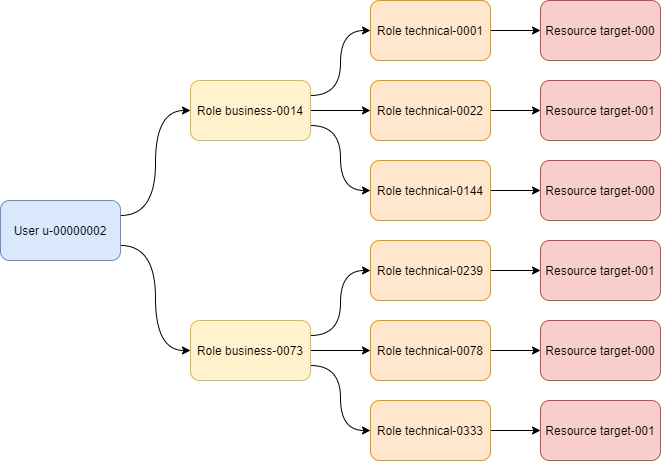
There is a two-level structure of roles:
-
User is assigned business roles (based on the value of
roleattribute on the primary source). An example:business-0014. -
Each business role induces
I≥ 0 technical roles, e.g.technical-0001 -
Each technical role is bound to a single target resource (e.g.
target-000) and is projected into a group object on that resource with the name liketechnical-0001. It induces:-
membership in the particular group,
-
a record in the
membershipattribute, containing the name of both business and technical role, e.g.business-0014-technical-0001.
-
The number of user assignments is driven by parameter A ≥ 0.
(Actually, both I and A can be also numeric intervals, to provide some randomness in the scenario.
Then we can speak of Amin, Amax, Imin, and Imax.)
The technical role looks like this:
<role oid="022c720a-3e94-409a-80f3-808d17f2d49a"
xmlns="http://midpoint.evolveum.com/xml/ns/public/common/common-3"
xmlns:ri="http://midpoint.evolveum.com/xml/ns/public/resource/instance-3">
<name>technical-0000</name>
<assignment>
<construction>
<resourceRef oid="f8574dcf-4541-46cb-97cb-9e0c9cdb8f99" /> <!-- target-000 -->
<kind>entitlement</kind>
<intent>group</intent>
</construction>
</assignment>
<identifier>g-0000</identifier>
<inducement>
<construction>
<resourceRef oid="f8574dcf-4541-46cb-97cb-9e0c9cdb8f99" /> <!-- target-000 -->
<attribute>
<ref>ri:membership</ref>
<outbound>
<expression>
<script>
<code>
// assuming user -> business -> technical role assignment path
assignmentPath[0].target.name + '-' + assignmentPath[1].target.name
</code>
</script>
</expression>
</outbound>
</attribute>
<association>
<ref>ri:group</ref>
<outbound>
<expression>
<associationFromLink>
<projectionDiscriminator>
<kind>entitlement</kind>
<intent>group</intent>
</projectionDiscriminator>
</associationFromLink>
</expression>
</outbound>
</association>
</construction>
</inducement>
</role>
Scenario Execution (Tasks)
The scenario runs in four stages:
| Number | Name | Description |
|---|---|---|
1 |
Initial import |
Initial import of accounts from sources, starting from the primary one. |
2 |
No-op imports |
Repeated imports of accounts from sources. They are called "no-op" because nothing changes on sources, so there should be no changes in repository nor on targets (except for e.g. some metadata). |
3 |
Source reconciliation |
Reconciliation of each source resource in turn. Again, without any changes on sources. |
4 |
User recomputation |
Recomputation of all imported users. Still with no changes. |
The execution of stages 2-4 is there to model situations when there are large reconciliation/recomputation tasks scheduled to ensure the eventual consistency of the system. In the future we might add some changes on sources to check the performance also in this case.
Technical Scenario Parameters
The conceptual parameters like S, T, SM, TM, U, A (and others) are driven
by Java system properties described here.
Sources and Inbound Mappings
Sources are defined using the following system properties:
| Property | Description | Symbolic name | Default value |
|---|---|---|---|
|
Number of source resources. |
|
1 |
|
Number of accounts on each resource. (This corresponds to the number of imported midPoint users.) |
|
10 |
|
Number of inbound mappings for single-valued dummy attributes → properties. |
|
1 |
|
Number of inbound mappings for multi-valued dummy attributes → properties. |
|
1 |
|
Number of values for each multi-valued dummy attribute. |
|
5 |
|
Random artificial delay imposed on each operation on the source system.
Not much relevant for search operations.
Useful for Since 4.9. |
0 |
Targets and Outbound Mappings
Targets are defined using the following system properties:
| Property | Description | Symbolic name | Default value |
|---|---|---|---|
|
Number of target resources. |
|
0 |
|
Number of outbound mappings for single-valued dummy properties → attributes. |
|
0 |
|
Number of outbound mappings for multi-valued dummy properties → attributes. |
|
0 |
|
Random artificial delay imposed on each operation on the target system. Beware, delays for group membership operations accumulate, so they may slow down the test significantly. When testing midPoint internal performance, this should be kept at zero. Since 4.9. |
0 |
Roles
Roles and their assignments are defined using the following system properties:
| Property | Description | Symbolic name | Default value |
|---|---|---|---|
|
Number of generated business roles. |
2 |
|
|
Number of generated technical roles. |
2 |
|
|
Fixed number of business role assignments per user.
If specified, then |
|
|
|
Minimal number of business role assignments per user. |
|
1 |
|
Maximal number of business role assignments per user. |
|
|
|
Fixed number of business → technical role inducements per business role.
If specified, then |
|
|
|
Minimal number of inducements per business role. |
|
1 |
|
Maximal number of inducements per business role. |
|
|
Extension Schema
The extension schema is a basic prerequisite for the testing scenario to work, because extension properties used by mappings are defined in it. The schema itself is governed by the following Java properties:
| Property | Description | Default value |
|---|---|---|
|
Number of single valued properties, i.e. |
100 |
|
Number of multi valued properties, i.e. |
10 |
|
Percentage of properties that should be indexed. Use an integer value between 0 and 100. E.g. if 25, then properties 0003, 0007, 0011, 0015, etc are indexed, while the others are not. If 50, then properties 0001, 0003, 0005, 0007, etc are indexed. |
0 |
Tasks
Tasks are driven by the following Java properties:
| Property | Description | Default value |
|---|---|---|
|
Number of worker threads for the import tasks. |
0 (i.e. single-threaded execution) |
|
Number of "no-op" runs of each of the import tasks. |
1 |
|
Number of worker threads for the source reconciliation tasks. |
0 (i.e. single-threaded execution) |
|
Number of runs of each of the reconciliation tasks. |
1 |
|
Number of worker threads for the recomputation task. |
0 (i.e. single-threaded execution) |
|
Timeout for individual tasks (in milliseconds) |
1800000 (i.e. 30 minutes) |
| Currently, it looks like the number of threads should be slightly less than the number of logical or virtual CPUs. However, this depends. Generally, one should try to find the number such that the throughput is maximized. |
| Multi-node tasks are not supported yet by this scenario. |
Other Properties
| Property | Meaning | Default value |
|---|---|---|
|
Custom label to be used for the scenario. |
Computed string in the form of (e.g.) |
Other Aspects
In the future we plan to other features, like template mappings, policy rules, organizational structure, and so on.
How to Run
The midPoint code has to be compiled (once) and then the test can be run repeatedly, with the same or different parameters.
Compilation looks like this:
mvn clean install -DskipTests -pl :story -am
And the execution then looks like this:
# # Single source, increasing number of mappings: 1, 10, 50, 100, 200 (both single and multi) # Number of accounts is decreasing from 2000 to 500. # mvn clean integration-test -pl :story -o -Pextratest -Dit.test=TestSystemPerformance -Dconfig=/.../postgresql.properties \ -Dsources.accounts=2000 -Dsources.resources=1 -Dsources.single-mappings=1 -Dsources.multi-mappings=1 -Dsources.multi-attr-values=5 \ -Dtargets.resources=0 \ -Droles.business.count=0 -Droles.technical.count=0 -Droles.assignments.count=0 -Droles.inducements.count=0 \ -Dschema.single-valued-properties=10 -Dschema.multi-valued-properties=10 \ -Dimport.threads=6 -Dreconciliation.runs=0 -Drecomputation.threads=6 mvn integration-test -pl :story -o -Pextratest -Dit.test=TestSystemPerformance -Dconfig=/.../postgresql.properties \ -Dsources.accounts=2000 -Dsources.resources=1 -Dsources.single-mappings=10 -Dsources.multi-mappings=10 -Dsources.multi-attr-values=5 \ -Dtargets.resources=0 \ -Droles.business.count=0 -Droles.technical.count=0 -Droles.assignments.count=0 -Droles.inducements.count=0 \ -Dschema.single-valued-properties=10 -Dschema.multi-valued-properties=10 \ -Dimport.threads=6 -Dreconciliation.runs=0 -Drecomputation.threads=6 mvn integration-test -pl :story -o -Pextratest -Dit.test=TestSystemPerformance -Dconfig=/.../postgresql.properties \ -Dsources.accounts=1000 -Dsources.resources=1 -Dsources.single-mappings=50 -Dsources.multi-mappings=50 -Dsources.multi-attr-values=5 \ -Dtargets.resources=0 \ -Droles.business.count=0 -Droles.technical.count=0 -Droles.assignments.count=0 -Droles.inducements.count=0 \ -Dschema.single-valued-properties=50 -Dschema.multi-valued-properties=50 \ -Dimport.threads=6 -Dreconciliation.runs=0 -Drecomputation.threads=6 mvn integration-test -pl :story -o -Pextratest -Dit.test=TestSystemPerformance -Dconfig=/.../postgresql.properties \ -Dsources.accounts=1000 -Dsources.resources=1 -Dsources.single-mappings=100 -Dsources.multi-mappings=100 -Dsources.multi-attr-values=5 \ -Dtargets.resources=0 \ -Droles.business.count=0 -Droles.technical.count=0 -Droles.assignments.count=0 -Droles.inducements.count=0 \ -Dschema.single-valued-properties=100 -Dschema.multi-valued-properties=100 \ -Dimport.threads=6 -Dreconciliation.runs=0 -Drecomputation.threads=6 mvn integration-test -pl :story -o -Pextratest -Dit.test=TestSystemPerformance -Dconfig=/.../postgresql.properties \ -Dsources.accounts=500 -Dsources.resources=1 -Dsources.single-mappings=200 -Dsources.multi-mappings=200 -Dsources.multi-attr-values=5 \ -Dtargets.resources=0 \ -Droles.business.count=0 -Droles.technical.count=0 -Droles.assignments.count=0 -Droles.inducements.count=0 \ -Dschema.single-valued-properties=200 -Dschema.multi-valued-properties=200 \ -Dimport.threads=6 -Dreconciliation.runs=0 -Drecomputation.threads=6 # # Increasing number of sources (having 50 + 50 mappings): 5, 10, 20 # Number of accounts is decreasing from 1000 to 500. # mvn integration-test -pl :story -o -Pextratest -Dit.test=TestSystemPerformance -Dconfig=/.../postgresql.properties \ -Dsources.accounts=1000 -Dsources.resources=5 -Dsources.single-mappings=50 -Dsources.multi-mappings=50 -Dsources.multi-attr-values=5 \ -Dtargets.resources=0 \ -Droles.business.count=0 -Droles.technical.count=0 -Droles.assignments.count=0 -Droles.inducements.count=0 \ -Dschema.single-valued-properties=50 -Dschema.multi-valued-properties=50 \ -Dimport.threads=6 -Dreconciliation.runs=0 -Drecomputation.threads=6 mvn integration-test -pl :story -o -Pextratest -Dit.test=TestSystemPerformance -Dconfig=/.../postgresql.properties \ -Dsources.accounts=500 -Dsources.resources=10 -Dsources.single-mappings=50 -Dsources.multi-mappings=50 -Dsources.multi-attr-values=5 \ -Dtargets.resources=0 \ -Droles.business.count=0 -Droles.technical.count=0 -Droles.assignments.count=0 -Droles.inducements.count=0 \ -Dschema.single-valued-properties=50 -Dschema.multi-valued-properties=50 \ -Dimport.threads=6 -Dreconciliation.runs=0 -Drecomputation.threads=6 mvn integration-test -pl :story -o -Pextratest -Dit.test=TestSystemPerformance -Dconfig=/.../postgresql.properties \ -Dsources.accounts=500 -Dsources.resources=20 -Dsources.single-mappings=50 -Dsources.multi-mappings=50 -Dsources.multi-attr-values=5 \ -Dtargets.resources=0 \ -Droles.business.count=0 -Droles.technical.count=0 -Droles.assignments.count=0 -Droles.inducements.count=0 \ -Dschema.single-valued-properties=50 -Dschema.multi-valued-properties=50 \ -Dimport.threads=6 -Dreconciliation.runs=0 -Drecomputation.threads=6 # # Increasing number of targets (having 1 source, 50 + 50 mappings): 5, 10, 20 # Number of accounts is decreasing from 1000 to 500. # mvn integration-test -pl :story -o -Pextratest -Dit.test=TestSystemPerformance -Dconfig=/.../postgresql.properties \ -Dsources.accounts=1000 -Dsources.resources=1 -Dsources.single-mappings=50 -Dsources.multi-mappings=50 -Dsources.multi-attr-values=5 \ -Dtargets.resources=5 -Dtargets.single-mappings=50 -Dtargets.multi-mappings=50 \ -Droles.business.count=0 -Droles.technical.count=0 -Droles.assignments.count=0 -Droles.inducements.count=0 \ -Dschema.single-valued-properties=50 -Dschema.multi-valued-properties=50 \ -Dimport.threads=6 -Dreconciliation.runs=0 -Drecomputation.threads=6 mvn integration-test -pl :story -o -Pextratest -Dit.test=TestSystemPerformance -Dconfig=/.../postgresql.properties \ -Dsources.accounts=500 -Dsources.resources=1 -Dsources.single-mappings=50 -Dsources.multi-mappings=50 -Dsources.multi-attr-values=5 \ -Dtargets.resources=10 -Dtargets.single-mappings=50 -Dtargets.multi-mappings=50 \ -Droles.business.count=0 -Droles.technical.count=0 -Droles.assignments.count=0 -Droles.inducements.count=0 \ -Dschema.single-valued-properties=50 -Dschema.multi-valued-properties=50 \ -Dimport.threads=6 -Dreconciliation.runs=0 -Drecomputation.threads=6 mvn integration-test -pl :story -o -Pextratest -Dit.test=TestSystemPerformance -Dconfig=/.../postgresql.properties \ -Dsources.accounts=500 -Dsources.resources=1 -Dsources.single-mappings=50 -Dsources.multi-mappings=50 -Dsources.multi-attr-values=5 \ -Dtargets.resources=20 -Dtargets.single-mappings=50 -Dtargets.multi-mappings=50 \ -Droles.business.count=0 -Droles.technical.count=0 -Droles.assignments.count=0 -Droles.inducements.count=0 \ -Dschema.single-valued-properties=50 -Dschema.multi-valued-properties=50 \ -Dimport.threads=6 -Dreconciliation.runs=0 -Drecomputation.threads=6 # # Increasing number of assignments (having 1 source, 5 targets, 50 + 50 mappings; each BR has 2 TRs): 5, 10, 20, 100 # Number of accounts is decreasing from 1000 to 500. # mvn integration-test -pl :story -o -Pextratest -Dit.test=TestSystemPerformance -Dconfig=/.../postgresql.properties \ -Dsources.accounts=1000 -Dsources.resources=1 -Dsources.single-mappings=50 -Dsources.multi-mappings=50 -Dsources.multi-attr-values=5 \ -Dtargets.resources=5 -Dtargets.single-mappings=50 -Dtargets.multi-mappings=50 \ -Droles.business.count=100 -Droles.technical.count=500 -Droles.assignments.count=5 -Droles.inducements.count=2 \ -Dschema.single-valued-properties=50 -Dschema.multi-valued-properties=50 \ -Dimport.threads=6 -Dreconciliation.runs=0 -Drecomputation.threads=6 mvn integration-test -pl :story -o -Pextratest -Dit.test=TestSystemPerformance -Dconfig=/.../postgresql.properties \ -Dsources.accounts=500 -Dsources.resources=1 -Dsources.single-mappings=50 -Dsources.multi-mappings=50 -Dsources.multi-attr-values=5 \ -Dtargets.resources=5 -Dtargets.single-mappings=50 -Dtargets.multi-mappings=50 \ -Droles.business.count=100 -Droles.technical.count=500 -Droles.assignments.count=10 -Droles.inducements.count=2 \ -Dschema.single-valued-properties=50 -Dschema.multi-valued-properties=50 \ -Dimport.threads=6 -Dreconciliation.runs=0 -Drecomputation.threads=6 mvn integration-test -pl :story -o -Pextratest -Dit.test=TestSystemPerformance -Dconfig=/.../postgresql.properties \ -Dsources.accounts=500 -Dsources.resources=1 -Dsources.single-mappings=50 -Dsources.multi-mappings=50 -Dsources.multi-attr-values=5 \ -Dtargets.resources=5 -Dtargets.single-mappings=50 -Dtargets.multi-mappings=50 \ -Droles.business.count=100 -Droles.technical.count=500 -Droles.assignments.count=20 -Droles.inducements.count=2 \ -Dschema.single-valued-properties=50 -Dschema.multi-valued-properties=50 \ -Dimport.threads=6 -Dreconciliation.runs=0 -Drecomputation.threads=6 mvn integration-test -pl :story -o -Pextratest -Dit.test=TestSystemPerformance -Dconfig=/.../postgresql.properties \ -Dsources.accounts=500 -Dsources.resources=1 -Dsources.single-mappings=50 -Dsources.multi-mappings=50 -Dsources.multi-attr-values=5 \ -Dtargets.resources=5 -Dtargets.single-mappings=50 -Dtargets.multi-mappings=50 \ -Droles.business.count=100 -Droles.technical.count=500 -Droles.assignments.count=100 -Droles.inducements.count=2 \ -Dschema.single-valued-properties=50 -Dschema.multi-valued-properties=50 \ -Dimport.threads=6 -Dreconciliation.runs=0 -Drecomputation.threads=6 ...
Note that the first command cleans the target directory in the story module. The other ones should not contain
clean maven goal, as to preserve the content.
The -Dconfig=… should point to a testing repository configuration.
The other -Dx=y flags define individual test parameters.
Results
The test provides four files for each test run:
| File | Description |
|---|---|
|
Summary information about the measured performance in a given run. |
|
Snapshot of the task progress during the course of the execution. It can be analyzed to see e.g. if there are any slowdowns as the repository is being filled in with the data. |
|
Standard |
|
Selected details (e.g. task statistics dumps) to be manually inspected, if needed. |
|
Machine-readable dump of the task object in the repository after it’s finished as part of the particular test. (Since 4.9.1.) |
Note that also test.log contains human-readable dumps of tasks during the course of tests executions, so this file is worth keeping, if possible.
1. Will be changed to
tasks.timeout soon.
2.
PREFIX consists of a timestamp and test characterization, so, for example, a particular summary.txt file name would be 1729758991398-1s-1m-3t-0m-1a-50u-summary.txt.
Was this page helpful?
YES
NO
Thanks for your feedback