System Requirements
This document describes system requirements for midPoint and its components.
Deployment Architecture
The midPoint deployment consists of the following units:
-
Connector servers (optional)
Each of these deployment units have slightly different characteristics and requirements, therefore each is described in a separate section below.
|
It is very difficult to provide a precise sizing for the midPoint system because the sizing mostly depends on the usage pattern, the number and character of running tasks, connected resources, synchronization and workflow processes, etc. It is very difficult to predict all the factors. This document provides estimations that are based on production experience from typical deployments, and general rules. These may not be directly applicable to your environment. The usual adjustment of the platform size and parameters during system operation according to the IT operation best practices is assumed in this estimation. |
MidPoint Server Sizing
MidPoint server is the main part of any midPoint installation. MidPoint server takes most of the load from user interaction and data processing. Therefore it is most sensitive to the CPU load and RAM size. The table below summarizes the recommended resources for typical scenarios:
| Minimum | Less than 5,000 users | 5,000 - 50,000 users | 50,000 - 100,000 users | More than 100,000 users | |
|---|---|---|---|---|---|
CPU |
1 core |
4 cores |
8 cores |
16 cores |
Custom sizing * |
RAM |
4GB |
8GB |
16GB |
16GB |
Custom sizing * |
Disk space |
2GB |
10GB |
20GB |
40GB |
Custom sizing * |
Disk I/O |
negligible |
negligible |
negligible |
negligible |
Custom sizing * |
* Deployments with more than 100,000 users are supported in midPoint. However, due to variability in large-scale environments, it is recommended to consult the specific hardware requirements with Evolveum Support.
Number of midPoint Server Instances
The sizing table above assumes that there will be a single midPoint instance (node). Multi-node midPoint instances are usually deployed for high availability reasons, and they are usually two-node systems. Each node needs to be dimensioned to take the full load of the system, therefore each node should be deployed according to the midPoint server sizing requirements.
Another reason for multi-node deployments is to isolate synchronous load (e.g. user interactions) and asynchronous load (e.g. tasks and processes). However, there is no universal rule for sizing such a system, and a case-to-case analysis and measurements are required. However, the values provided in the table above may be used as the starting point.
Database System Sizing
Database system is used to store the vast majority of midPoint data.
The load on the database system is most sensitive to the size and character of the data, the usage patterns, and also the type and configuration of the used database system. Use the values below as general guidelines and adjust them to fit your use case. For a more precise estimate, consult the Evolveum database engineers.
| Minimal | Less than 5,000 users | 50,000 - 100,000 users | More than 100,000 users | |
|---|---|---|---|---|
CPU |
1 core |
2 cores |
8 cores |
Custom sizing * |
RAM |
2GB |
3GB |
12GB |
Custom sizing * |
Disk space |
1GB |
5GB |
20GB-100GB for 3 months audit |
Custom sizing * |
Disk I/O |
small |
medium |
medium to high |
Custom sizing * |
* Deployments with more than 100,000 users are supported in midPoint. However, due to variability in large-scale environments, it is recommended to consult the specific hardware requirements with Evolveum database engineers.
The recommended values assume that midPoint is used to store operational data, and only a reasonably small amount of historical data (e.g. audit records). If you are planning to use midPoint to store historical data, a proper data retention and capacity planning must take place before evaluating the database sizing.
|
Shared vs dedicated database
Since version 4.4, midPoint uses a native repository that relies on PostgreSQL. It is recommended to use a separate server for the database even for smaller midPoint deployments. You may even consider separate databases for audits, and for the repository, as the access patterns and sizing are quite different. |
Connector Servers (Optional)
Connector Servers are small software components that act as a proxy for connectors that cannot run inside midPoint. Deployment of these components is quite rare.
Resource requirements of connector servers are extremely small. It is usually too small to measure: a tiny portion of CPU and RAM, and a disk space measured in megabytes. We strongly recommend deploying these components on shared servers.
High Availability
There are several approaches to implement high availability (HA) for midPoint deployments. Each strategy has different characteristics and costs:
|
Not business critical
Note that midPoint is an identity management system, and as such, it is seldom a business critical system. If midPoint fails, the impact is usually negligible. The integrated systems (resources) are independent of the midPoint instance by design. Therefore midPoint failure does not influence the operation of such systems in any significant way. A midPoint failure can influence management capabilities, password resets etc. But these functions are usually not critical for operation, especially if the outages of midPoint are short (minutes). Even longer outages (hours) do not usually impact operation of the infrastructure in any significant way. This is important to keep in mind when choosing the right HA strategy. |
Virtualization-based HA
The easiest way to implement high availability is to use HA features of the underlying virtualization infrastructure. In case that the host machine running midPoint virtual machine fails, it is easy to fail over the whole virtual machine to a different host. There is obviously some downtime while the failover takes place (usually a few minutes). However as midPoint is not a critical system, this is more than acceptable.
This is a very cost-efficient failover strategy. It is recommended especially if midPoint and the database run on the same virtual machine.
In this scenario, midPoint is set up to run in a single-node configuration (default) and no extra configuration is necessary. The HA mechanisms are completely transparent. MidPoint has internal mechanisms to recover from system outages that will be automatically used in this setup after the failover.
Load Balanced with a Shared HA Database
In this scenario, there are several instances of midPoint servers that are load balanced on the HTTP layer by using a standard HTTP load balancer (sticky mode). All the midPoint servers are connecting to the same database which has internal HA mechanisms. MidPoint is sharing the database engine with other applications.
This set-up assumes using a shared database instance that already has HA mechanisms. As this database is shared with several applications, then even active-active HA mechanisms are justifiable as the cost of the HA set-up is divided among several applications.
Load Balanced with a Dedicated Database
In this scenario, there are several instances of midPoint servers that are load balanced on the HTTP layer by using a standard HTTP load balancer (sticky mode). All midPoint servers are connecting to the same database which has internal HA mechanisms. The database engine installation is dedicated to midPoint.
This is the most expensive set-up and it is seldom justifiable due to the cost of the HA database system. The usual compromise in this case is to use active-passive database HA strategies. Due to the low criticality of midPoint, this is usually acceptable from the operational point of view.
Software Requirements
Refer to the midPoint Releases documentation for software requirements.
Infrastructure Requirements
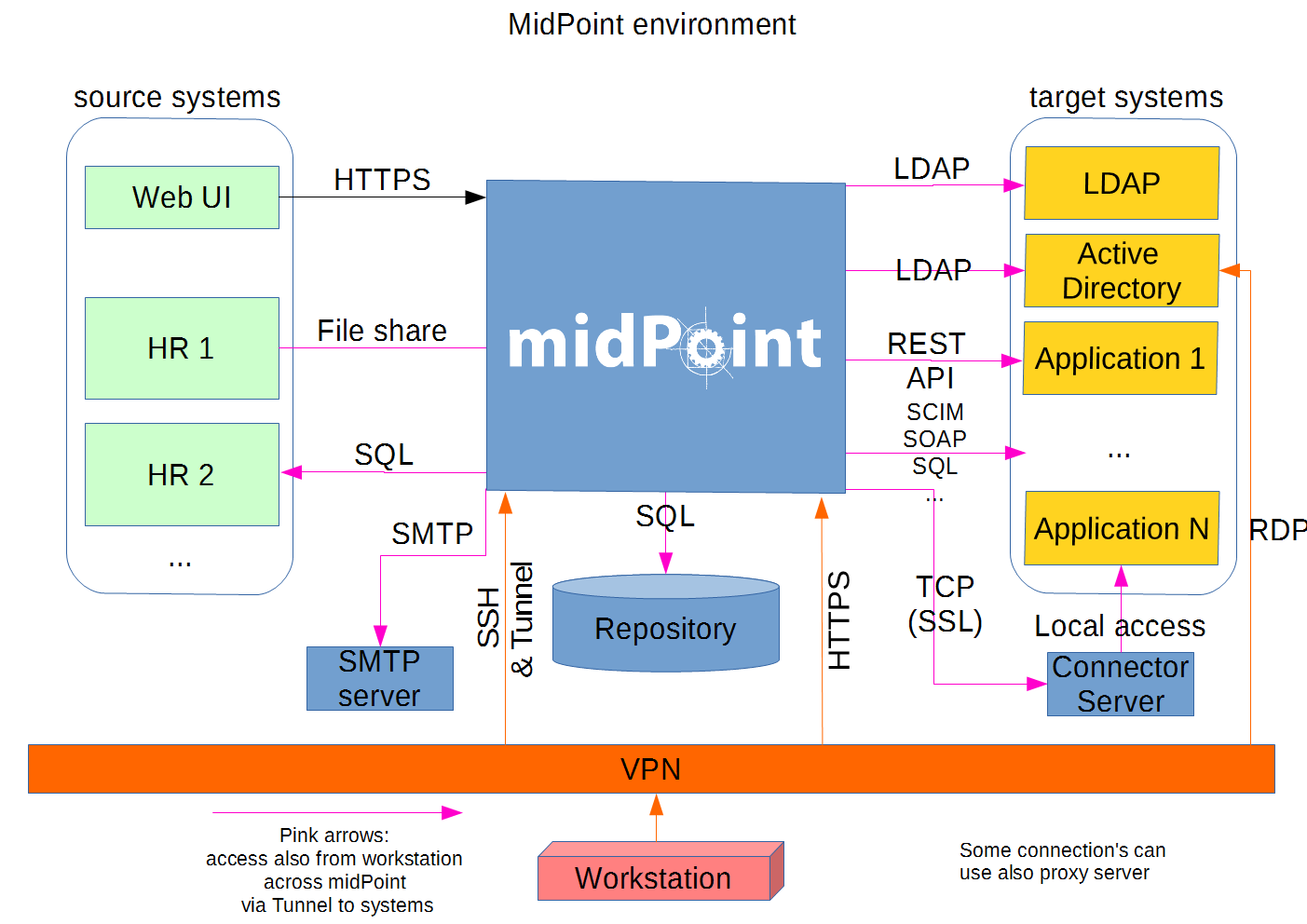
When you start an IAM project, not only midPoint servers but also the database and load balancer (if required) must be prepared. You need to have access to the infrastructure in which these servers are running, and also to the source and target systems. In most cases, the infrastructure is prepared by the administrators on the customer site. The next schema represents a basic scenario:
You can see one midPoint installation with sample connections.
In most cases, the biggest square with the midPoint logo is represented by a Linux virtual machine with preinstalled Java SE development Kit (for example OpenJDK), Apache Tomcat from a Linux repository prepared to run as a service, and tools like telnet, wget, mlocate.
A Windows server is rarely used.
You can install the latest midPoint release, however in most cases, the installation is provided by an Identity engineer (supplier).
For the database repository, an existing DB server is usually used. You have access to it over the SQL protocol (for example MS SQL on the default TCP port 1433, 1521 for Oracle, etc.) from the midPoint server. Do not forget to configure your firewalls. Also, a new DB schema is created for midPoint with a new technical user and DB owner permissions. Sometimes we have a separate DB server or can we use a DB server in the same virtual machine where midPoint is installed (only in single-node mode).
If e-mail notifications are needed, access to the SMTP server and also a new account with send privileges is required. You may also need access to an SMS gateway, and have the account privileges to send SMS.
Many deployments are provided remotely. The best practice is to prepare a secure VPN access for each team member separately with direct access to the midPoint server over SSH. This should have enabled tunneling and HTTPS access (8443 is the default internal Tomcat port, or 443 with transformation to the Tomcat port). In most cases, midPoint Web UI (self service) is also accessible via HTTPS for all employees in customer intranet.
Other source systems are HR, for example, represented as an Excel table (HR 1 in the schema). An HR manager saves the current content after each change (or once a day/week) into a CSV file to the location where midPoint can read, proceed & rename the CSV (File share). If there is a sophisticated HR system, we can access the employee and organizational structure data through prepared read-only DB views. This is done directly through SQL (HR 2 in the schema) prepared by the HR supplier - an SQL account is required. Or we can use the existing SOAP or REST APIs to read these data - API account/key is required.
The most frequently used target system is LDAP (for example, Open LDAP with its standard port 636 or 389), or Active Directory that is used when we also need Remote Desktop Connection (RDP). This is typically used directly from the workstation, however, tunneling through the midPoint server is also possible. Also, a technical account with full permissions to the respective DN or domain is required.
Connection to other target systems can be established over REST API (Application 1 - HTTPS), SOAP, SCIM (Application 2, 3, … - HTTPS), SQL, or some other proprietary service (for example SAP and JCo). With those, you will need to enable API, open your firewall on servers where the system is running, and create an account with respective access to manage identities. Sometimes, when cloud services are used (for example Office 365), access to internet is granted over a proxy server.
In some cases, midPoint may also need to have local access to the system (Application N). In this case, a connector server component is installed on the server where the system is already installed, for example to run some scripts to prepare the home directory.
If the situation requires two or more midPoint nodes, the schema looks like this:
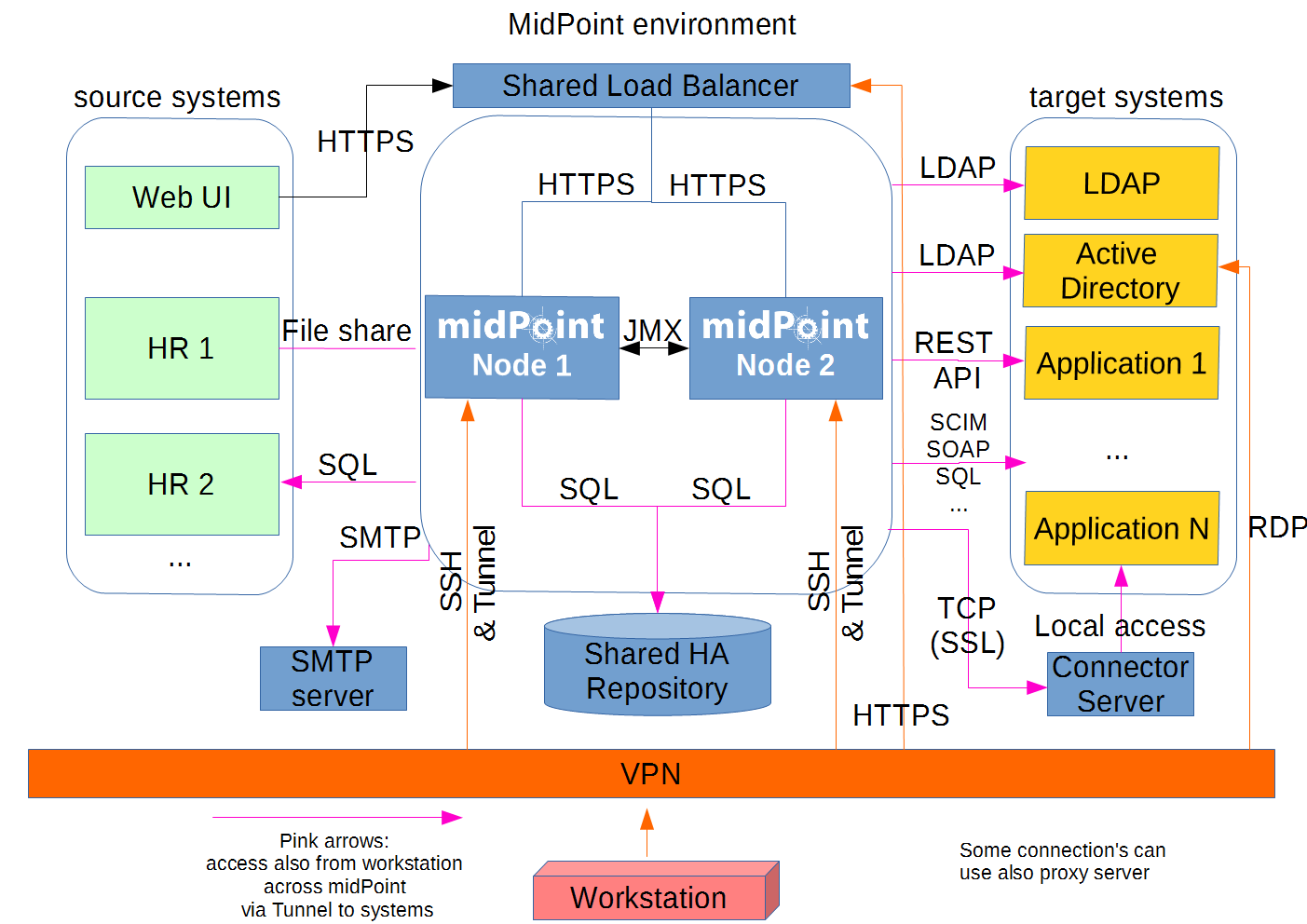
Identity engineers need VPN access to all nodes (node 1, node2: SSH & Tunnel, and also HTTP/S access to the local Tomcat that can be tunneled). Node jobs are synchronized over JMX.
Each midPoint node needs to have access to the SMTP server (if notifications are required), shared HA DB Repository, and all source and target systems to have full HA support. When a node is down, other nodes need to be able to replace all of its jobs.
End users and identity engineers use midPoint Web UI over a load balancer (HTTPS).
You can check that connections to all source or target systems are working using the following tools: ping, telnet, and wget.
You can use them from the midPoint server and also from the workstation (once tunnels have been configured).
Environment Requirements
In IAM projects, at least two environments are typically used: test & production. In many cases, there is also a local midPoint installation on the identity engineer’s workstation, and another development environment in the customer’s infrastructure.
The best practice is to use a configuration that is as similar as possible in all of these environments. However, it should also be completely isolated without access, for example, from the test midPoint environment to production Application 1. VPN can be shared.
For identity development, it is recommended for the test and production environments to have the same operating system (and version), application version, and data for all source and target systems. Any differences may lead to situations where something is working and is well tested in one environment, but does not work in another environment.
If data are sensitive, and cannot be used in the development phase, you can obfuscate them and only use a part of them as a sample. However, the schema and all attributes that you are using need to be used the same way as in the production environment to minimize differences.
If you are also deploying the solution to production, you need to have access to the production environment and the data there. It is not necessary to obfuscate data for the test or development environments, because the same identity engineer is responsible for the development, testing and deployment.
|
Irrespective of if you use the original or obfuscated data, you need to be able to use production data in the development phase to prevent future issues. Note that running an IDM project involves consolidating users, the organizational structure, and accessing data. Every discrepancy and exception will surface in production, and you will need to decide how to handle it. That is why it is best to run your IDM project when you are not doing acceptance testing, have problems in production, or hard deadlines. |
Was this page helpful?
YES
NO
Thanks for your feedback