Outcomes Of MidPrivacy: Provenance
This is a summary of outcomes of first phase of midPrivacy initiative: Data Provenance Prototype.
Axiom
Key component of the solution is a data modeling language capable of expressing not just data models, but also metadata models. We have been researching for an existing data modeling language that would fit our needs. Unfortunately, there seems to be no popular or ready-to-use data modeling language with appropriate metadata modeling support. This result was not very surprising. Our team is struggling to adapt XML Schema definition (XSD) language for our purposes well over a decade. Most popular data modeling languages provide capabilities that are roughly equivalent to XSD. We have realized that we need to make a major leap in technology to satisfy our needs. Therefore we have designed our own data modeling language: Axiom.
Axiom is a general-purpose data modeling language. On the surface, Axiom is similar to XSD, JSON Schema or any other modern data modeling language. But Axiom goes much deeper. Axiom introduces a concept of inframodel that allows data models to manipulate fundamental concepts of the language and data structures. The concept of inframodel was used to define metadata models. This approach is used in Axiom to model all the metadata for midPoint. As far as we know this is a very unique approach, an approach that we have not seen in any existing language.
We have invested significant amount of time and effort to design Axiom. We have expected that designing a new data modeling language will not be easy. Existing languages could not be used for inspiration when designing the crucial "meta" and "infra" concepts. It took several design iterations and some amount of rework to get to Axiom 0.1 specification.
Overall, Axiom is a very promising development and we are very enthusiastic about the results. We have invested significant amount of time to create Axiom design, language specifications and prototype implementation. We are aware that this is not yet the final version of Axiom and that we will probably have to make adjustements along the way. However, we are quite optimistic, as we have chosen one of the most challenging scenarios (metadata) to validate viability of Axiom.
Relevant links:
-
Axiom Concepts explains concept of Axiom inframodel
-
Implementation of Axiom processors in midPoint source code
Metadata Schemas
Axiom provides capability to create metadata models. However, we still need the actual models. Initial analysis conducted before the first milestone of the project already indicated that there is no metadata or identity provenance schema that we could readily reuse. Therefore we had to create suitable metadata schemas.
Design of some metadata schemas was relatively straightforward, especially the schemas that were specific to midPoint. However, design of generic identity provenance schema proved to be particularly challenging. There does not seem to be any broad agreement what provenance really means and how provenance metadata should look like. We have spent significant amount of time designing the schema that can both suit the way how midPoint is dealing with data and that can express generic concepts of data origin and provenance. We had to create rough design of future data protection features to make sure our provenance concepts are at least roughly correct. We ended up with a provenance metadata design that we believe could work.
The schemas include provenance, storage, transformation, process and provisioning metadata. Design of provenance metadata is based on our analysis and estimates of metadata requirements, as no other source was available for the design. Previous midPoint versions did not utilize provenance metadata, therefore we could not build on our past experiences. However, storage, process and provisioning metadata are based on metadata that were used in past midPoint versions. Transformation metadata are based on diagnostic experiences from midPoint maintenance and deployments.
We have put metadata schemas to work by implementing prototype code for metadata mapping and transformation. This prototyping lead to a realization, that we need to fundamentally change the way how we deal with metadata. As each data value may originate from several sources, the metadata need to be multi-valued (see below).
Prototype Code
All essential parts of the metadata functionality was prototyped in midPoint and it will be part of midPoint 4.2 release. The solution consists of following parts:
-
Axiom processing code. Parser and processor for Axiom models were implemented in a separate component in midPoint source code. The Axiom processors were integrated in Prism component that drives the data processing in midPoint. In midPoint 4.2, Axiom and XSD co-exist in Prism layer side-by-side. XSD is used to process bulk of midPoint data models. Axiom is used to process metadata schemas.
Axiom processing code is located in
infra/axiomcomponents in midPoint source code. -
Metadata schemas, including data provenance schema. Metadata schemas were designed and specified by using Axiom language.
Metadata schemas are located in
infra/schemacomponent in midPoint source code. -
MidPoint integration code, including functionality for metadata mapping and value consolidation. MidPoint core processing code (a.k.a. model subsystem) was updated to accommodate metadata-processing code. MidPoint is processing metadata along with the data, considering metadata being an integral part of the processing. MidPoitn data mappings are processing both data and metadata. This approach required significant changes to midPoint data processing algorithms, especially for value consolidation algorithms. This was quite a demanding task. Work on development, integration and testing of this code was a major contributor to discovery of metadata multiplicity and value equality issues. Major issues were discovered in the validation part of the project and significant improvements were implemented. There is also a new configuration schema and supporting code that allows configuration of metadata behavior for individual data items. The configuration is still not entirely straightforward, but the mechanism is more than sufficient for the purposes of this prototype.
Integration code is located in several components, but most of the code is in
model/model-implcomponent in midPoint source code. -
User interface prototype for displaying the metadata. Several development iterations of user interface code were created. The metadata schemas evolved during the project, and our understanding of the metadata problem evolved with them. Simple user interface that were focused on mere feasibility of metadata presentation was developed during first milestone. This user interface was improved several times, resulting in more refined user interface that is present at the end of the project. However, we are almost certain that even this form of user interface is not the final one and that more work is needed (see discussion of user experience below).
User interface code is located in
gui/admin-guicomponent in midPoint source code.
Market Evaluation
We started midPrivacy project with potential use-case analysis. We had some of the use-cases in mind from the beggining, but we wanted to confirm thier market potential. Moreover we wanted to discover additional use-cases and understand how other people think about metadata and privacy protection in the identity management area.
We discovered that we are pioneers in the area. We were trying to reach to people who are interested in the same area but we couldn’t find any. For the same reason we had a hard time to gather use-cases. At the end we didn’t get use-cases for data provenance, or metadata processing in general, but we gather various identity management related scenarios where we figured out on our own how midPrivacy project might help.
With constructed use-cases we started a survey in hope, that people will understand the topic better, start seeing potential of metadata processing and help us understand their needs. It was a partial success. We got nice spectrum of results that assures us that we are working on something that has potential for people. On the other hand, the participation in the survey was fairly low. Lot os people opened the survey, but most of them didn’t come through. That just strengthen our feeling we are digging in a new territory and people are not fimiliar with it yet.
From the day one we know that metadata will help with midPoint internal features as very convenient side-effect. Tracing the origin of the data as well as transformation on the way is significant help with debugging identity management processes. We also discovered the provenance metadata can help with maintaining multivalue attributes which value is merged from different sources. During of delta updates of such attributes was impossible to evaluate if a particular value should be removed or not, because we didn’t know if was provided byt the other source or not. With provenance this problem is becoming trivial.
At the end of the current phase of the midPrivacy project we have prepared a technical demo demonstrating our result. We have organized a public workshop where the demo was shown together with presentation about the whole project. The workshop was successful. We confirmed that the metadata has a potential thanks to the polls that were filled out by workshop participants, but it will require some fine tuning before it will be production ready. Nevertheless some people are seeing the value from them even with current limited capabilities. Workshop was attended by about 20 people which is nice, but still cannot give us the complete picture about the market.
To sum it up, there is demand, but also a lot of uncertainty and confusion. E.g. very little interest in the survey. We suspect that the cause may be very limited understanding of metadata concepts in the community. We have created "Identity Metadata In A Nutshell" document to boost understanding of metadata concepts. However, the effects are likely to be long-term, and it will require a lot of time to "sink in".
Discoveries and Challenges
Progress on the prototype was not entirely smooth. Which was mostly expected due to the exploratory nature of this project. However, the difficulties during project execution brought some interesting and surprising discoveries.
Data Inframodel
Axiom data modeling language was developed with one specific requirement in mind: metadata support. However, we did not want to "hack" the support into the language. We tried similar "hacking" approaches with XSD and they usually turned into maintenance problems in the long run. Therefore we have experimented with Axiom concepts in an attempt to design metadata as a natural extension of basic Axiom concepts.
We were experimenting with models of data models (metamodels) and related concepts.
However, we found that none of the metamodels and metametamodels lead to a desired solution.
We have realized that we are thinking in a wrong dimension.
We do not need to go beyond (meta) the data model, we need to go under (infra) the data model.
We need to model the underlying structure of the data.
In this case, it is not important that the data structure has an optional string field foobar.
The important thing is that the data structure is composed of items such as properties and containers, that the items have values and what we can say about the values.
We have dubbed this concept inframodel, as it is a model of underlying structure of the data.
Then we can implement value metadata simply by extending the data structure of item value in the inframodel.
Such extension will result in each value of each item in all the data types to be able to hold metadata.
The concept of inframodel allowed us to make extensions to the fundamental structure of data in a very simple and elegant way.
Data Equality Problem
Data equality is relatively simple matter.
Strings John Doe and John Doe are clearly the same.
There are some issues such as case sensitivity and canonization, but overall, it is not very complicated.
However, metadata significantly complicate the equality problem.
Should John Doe and John Doe be considered equal, even if such values have different metadata?
There seems to be no clear answer here.
Obviously, we want to consider the values to be equal even if the metadata differ, unless the metadata differ too much.
But how much is too much?
We have not found any theoretical data on this issue, therefore we have experimented with this problem from a practical side.
MidPoint has a built-in mechanism for value consolidation.
The consolidation, simply speaking, puts together values that are considered to be equal - or similar enough.
The result is an authoritative value that has to be provisioned or deprovisioned (or rather a delta).
The consolidation algorithm was originally used to merge values produced by midPoint mappings.
In midPoint 4.2 we have added metadata to the mix and made the consolidation process metadata-aware.
This moved proved to be much more complex than expected, but it resulted in a lot of "experimental data" and experiences.
It looks like that provenance metadata play a crucial role in value equality evaluation. We made our algorithms work by relying on the provenance metadata when comparing values. If provenance metadata match, then we assume that the value was produced by the same source and it is considered to be equal. If provenance metadata do not match, then we consider the values to be different. Now, there is still an issue what provenance metadata match means. We have not required complete equality of the provenance metadata and we have ignored differences in some fields, such as timestamps. This approach seems to work as a general rule.
However, this leads to an interesting situation: data values are equal, but metadata do not match. We cannot simply eliminate one of the values, as they technically are not the same. Yet we cannot keep the both as the data part is the same. This problem lead to the discovery of metadata multiplicity and to the design of the concept of yield.
Metadata Multiplicity
One of the least expected discoveries was metadata multiplicity. It looks like metadata are inherently multi-valued, as a single data value may come from several places.
See Metadata Multiplicity Problem for detailed explanation of the issue.
We have not suspected this issues at the beginning of the project. There was nothing in the initial research that would suggest this kind of issues. We have observed first signs of this issue approximately in the middle of the project, but at that time we have thought that the issues is limited to provenance metadata. It was only quite late in the project that we have realized that this multiplicity is an inherent property of all metadata. We were already in the validation phase of the project. However, we have decided that this is a significant discovery and that we have to adapt our data structures and algorithms, otherwise the validation phase would be much less meaningful. We have invested our own funds to support this effort. Improvements to prototype code worked well. There are still some remaining issues and inspiration for future work, but the prototype functions acceptably well.
Yet, the metadata multiplicity, the concept of yields and its relation to data protection is perhaps the most surprising discoveries in this project.
Data Protection
It is perhaps an intuitive understanding that metadata, and especially provenance metadata, are related to data protection. However, the depth of this relationship that we have discovered during this project came as surprise nevertheless.
MidPrivacy initiative is a long-term initiative to implement data protection and privacy features in midPoint. Also, in midPoint, we have a tradition to design data structures and mechanism in such a way that we are looking ahead to quite a long future. Therefore we took the opportunity to validate our provenance metadata schema using a "thought experiment". We tried to create a rough design for interaction of provenance metadata and data protection features.
Basis for data processing is one of the fundamental concepts of data protection. We have experimented with the concept of basis in initial phase of midPrivacy initiative (phase 0). The results were promising. Unfortunately, we were not able to secure funding for further experiments. Despite the limited resources, we were able to gain some insights how the concept of basis can work in identity management and data protection systems. Therefore, we have tried to explore how provenance metadata relate to the concept of basis for data processing.
Even though it may seem obvious in the hindsight, we have found that there is a very deep relation between data provenance and the basis for data processing. In fact, it almost looks like the basis is part of data provenance information.
Most data protection principles mandate, that the data can be processed only if there is a valid basis for the processing. The data are acquired from the source for a particular reason, and that reason forms basis form the processing. The basis seems to be integral part of the provenance information, as the data cannot be processed for any other reasons and for any other purpose. If there is a desire to process data for a different purpose, the data need to be re-acquired - even data values are the same and the data originate from the same source as the data that we already have. For example, the re-acquisition may take form of securing additional consent from the user. The re-acquisition "unlocks" the data to be used for additional purpose.
The situation may be even more complex.
When we have a basis to process person’s name, we can legally process the value Jane Smith.
And when Jane gets married, we can probably go on and update that value to Jane Brown and still do that legally.
The basis applies to data item (person’s name), not to a particular value of the item (Jane Smith).
This is relatively simple case.
We have focused on this case during the initial phase of midPrivacy initiative.
We have used concept of midPoint assignment to represent the basis for data processing.
However, there is a different case. There are multi-valued items that combine information from several sources. Affiliation is a good example of this case. Each value if the affiliation data item may originate from a different source. Different bases for processing may apply to every individual value. Therefore we have to record the basis in the value metadata. An assignment may still be needed to represent the bases (e.g. scope of the consent, duration, etc.). Assignment is likely to be needed to make sure that the value is properly maintained, e.g. in case that the organization is renamed. However, the affiliation item is likely to combine values referenced by several assignments. It would not be feasible to distinguish the values without referencing the basis in the value metadata (directly or indirectly).
Once again, this brings us back to the concept of yield. There may be several bases for data processing that apply to a single value. We cannot "flatten" then, we have to manage each basis individually as they may have independent lifecycle. The obvious solution is to record the basis in yield, and maintain separate yield for each basis. An elegant solution would be to reference the basis in provenance metadata, which would make management of overlapping bases quite straightforward.
See Provenance, Origin and Basis for a more detailed explanation of the concepts.
Relation To Data Portability
Data provenance has an obvious and significant overlap to data portability. However, we have not dealt with data portability specifically. Our exploration of data provenance was limited to the "scenery" as it was seen by midPoint. We have considered the systems that are directly connected to midPoint, but we haven’t explored any further.
We have prepared a proposal to NGI Data Portability and Services Incubator (DAPSI), with an intent to follow-up on our work with metadata. Unfortunately, our proposal was not selected. We hope that we will have better success in securing funding in the future, as our work suggests that there may be interesting opportunities for exploration in data portability area.
Metadata User Experience
Presentation of metadata to users is a major challenge. We have expected that, therefore we have started to work on user interface changes ahead of schedule. User interface went through several design and implementation iterations.
Early prototype was implemented ahead of schedule in May 2020. The purpose of this prototype was to lay basic foundation in existing GUI code and evaluate feasibility of GUI implementation. Perfect functionality was not expected and user experience was not the primary goal.
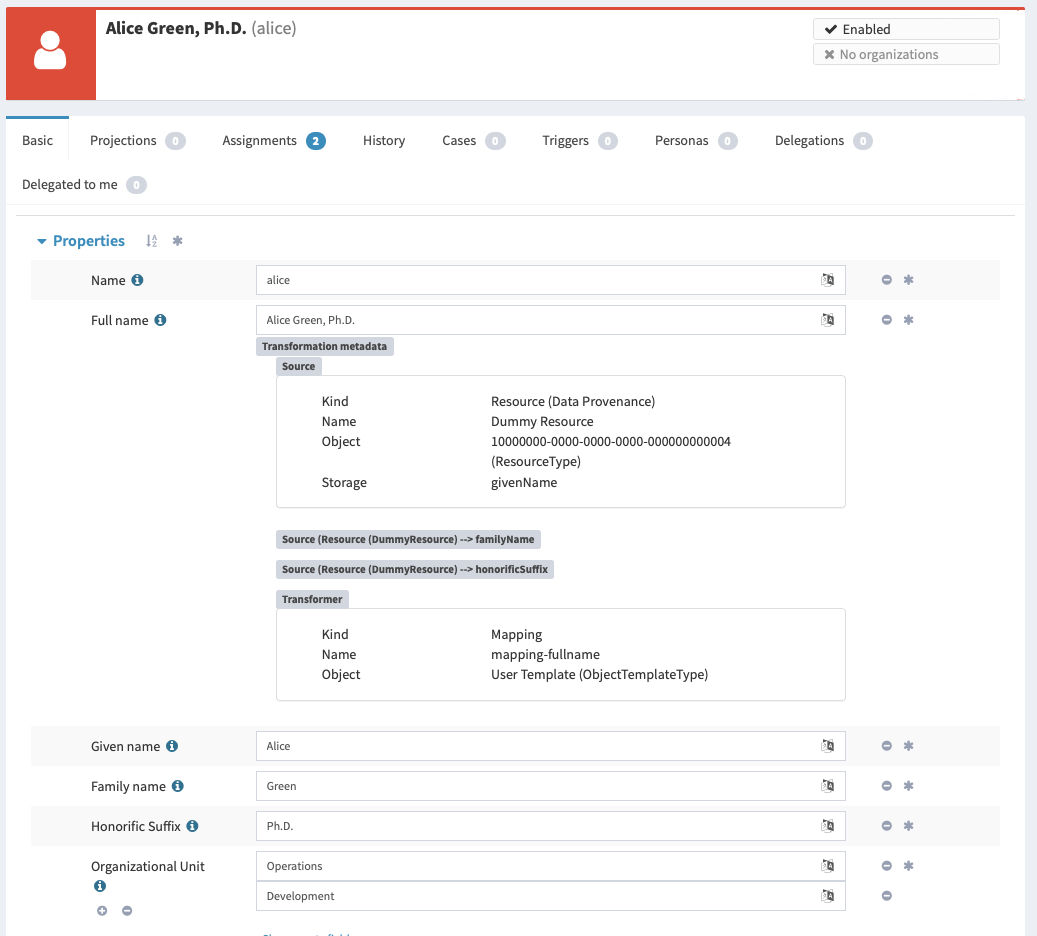
Figure 1. Metadata GUI, Early prototype, May 2020
The work on GUI resumed in August 2020. First usable metadata GUI was implemented.
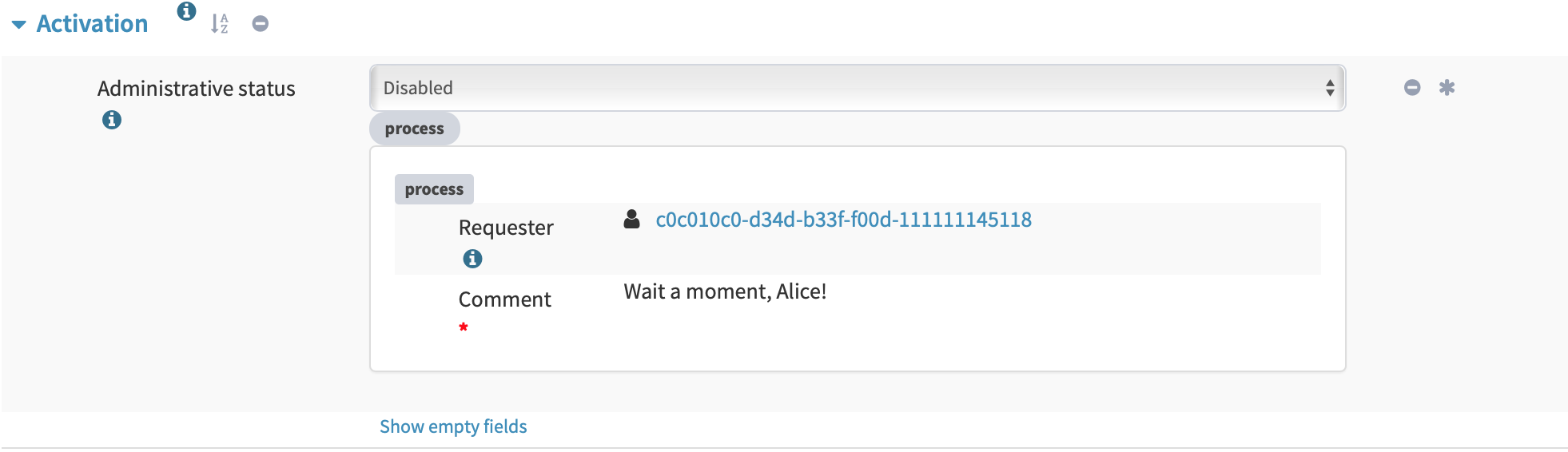
Figure 2. Metadata GUI, First update, August 2020
This implementation produced user experience feedback. Therefore user experience improvements were implemented.
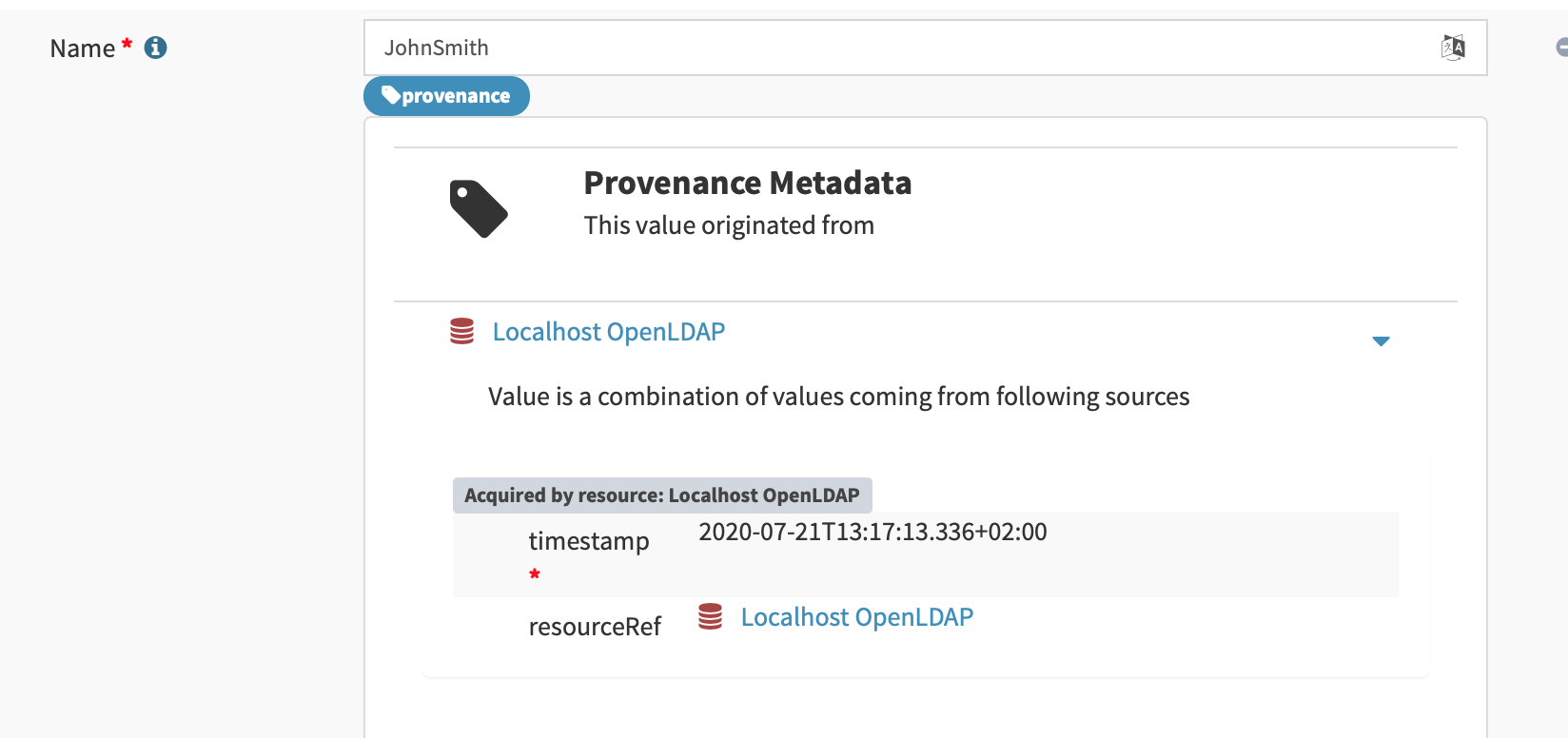
Figure 3. Metadata GUI, Second update after UX feedback, August 2020
Provenance metadata schemas have evolved in parallel to the GUI implementation. At this stage the GUI reflected the concept of yield in provenance metadata. This was still before we have discovered the multiplicity problem.
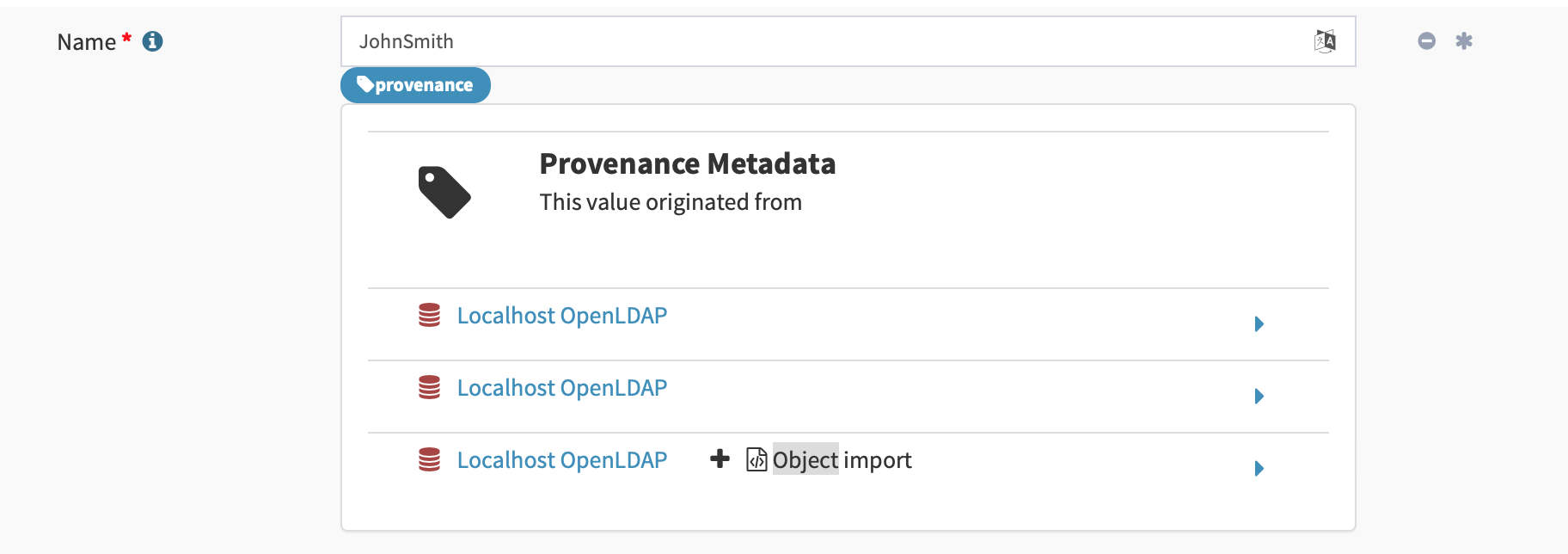
Figure 4. Metadata GUI, Third update, implemented concept of yield, before metadata multiplicity, August 2020
Implementing metadata multiplicity caused structural changes in GUI code. Despite that, we have tried to maintain existing look and feel that seemed to work acceptably well.
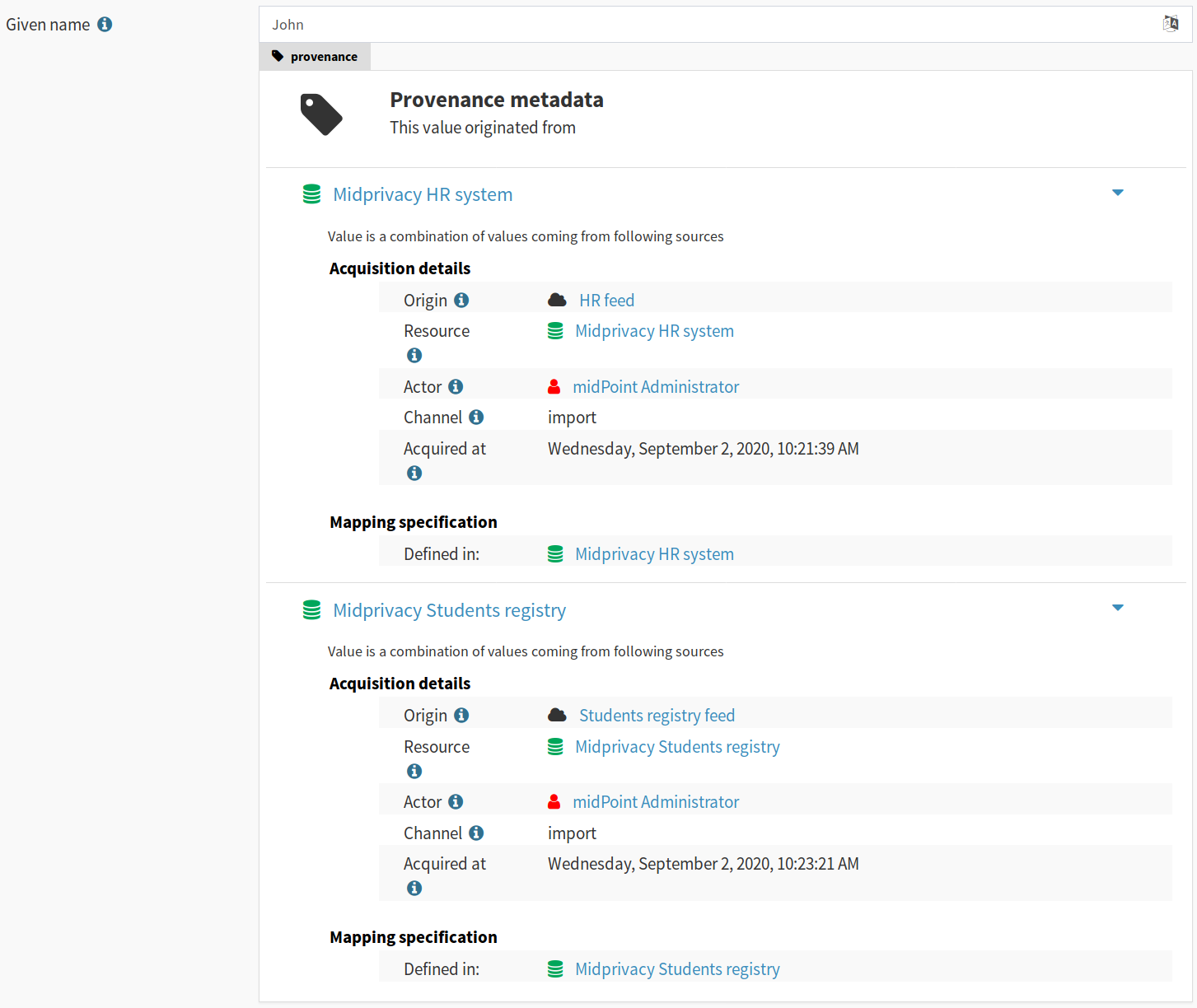
Figure 5. Metadata GUI, Final update, after metadata multiplicity, September 2020
Overall, metadata presentation proved to be very challenging. We did not need any special user experience testing, as user experience problems were immediately obvious during internal testing of GUI prototypes. One of the challenges was presentation of a complex metadata structures in a limited space on screen. We have used expandable GUI elements to resolve this challenge. However, the primary challenge was to present metadata structures in a form that is understandable to users. Due to the limited project scope we have to focus on provenance metadata only, but even that proved challenging. The multiplicity problem affected user interface as well. We have chosen to present yield and acquisition data structures in a simplified form and enrich the presentaion with explanation texts. This improved understandability of the interface, at least for users that were familiar with identity management concepts. However, we are afraid this form of metadata presentation will not be suitable to ordinary users and that the user interface will need more work in the future.
Other Challenges And Inspiration For Future Work
The project was full of challenges, both simple and complex. The challenges were expected due to the prototyping nature of the project. Significant challenges were already mentioned. Record of other challenges can be found in a separate description of project challenges.
The challenges and discoveries provided unique inspiration for future work. The ideas for the follow-up activities are documented in "Future Work" document.
Side Effects
The project produced outputs that were not entirely intended at the beginning of the project, yet they are very helpful. Many thoughts and design details of Axiom language concepts fall into this category. Perhaps the most significant side effect is "Identity Metadata In A Nutshell" document. This document provides an easy-to-follow introduction to metadata concepts and their use in midPoint.
See Also
Was this page helpful?
YES
NO
Thanks for your feedback