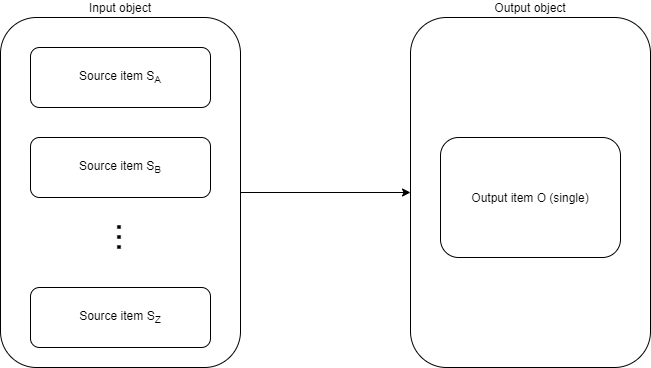
Metadata mapping model
See also:
-
Expression for background information on expression evaluation,
-
Processing expressions for information on processing "simple" data expressions,
-
Processing mappings for information on processing "simple" data mappings.
Data mapping
Data mappings transform source item(s) - e.g. SA, SB, …, SZ - to output (target) item - e.g. O - in the context of a single object.
Each source has some old and new values. Let us denote them a1, a2, …, ana → a1', a2', … , ama' for source SA, and similarly for other sources.
The output consists of plus, minus and zero set of values, denoted op1, op2, …, opk for plus, om1, om2, …, oml for minus, and oz1, oz2, …, ozm for zero set.
So the above picture can be augmented with the values like this:
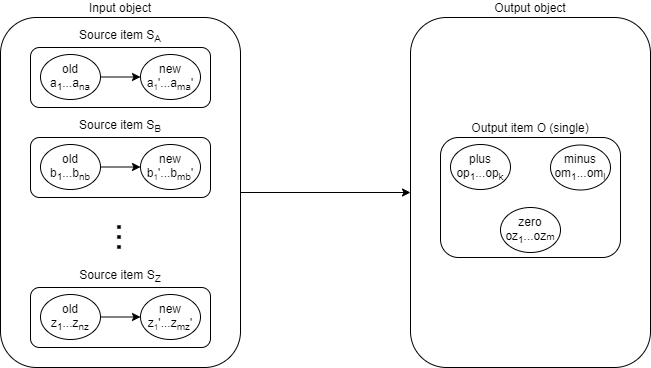
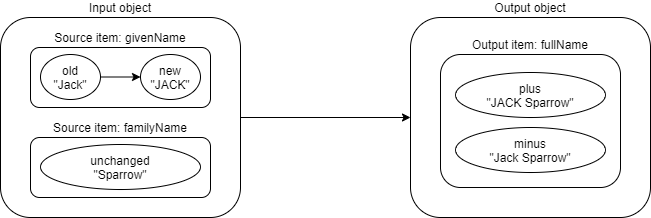
An example:
| Why is there only one source object? In fact, with the advent of linked objects one can imagine a mapping that would operate on a set of all objects connected to the focus via particular link type. See Multi-objects mappings. |
If we use combinatorial evaluation (this is the case for most of the time) the values are constructed like this:

i.e. output value oj (or, sometimes, more values e.g. ok, ol, …) are computed from values aia, bib, …, ziz from sources SA, …, SZ, respectively, taking a combination of ia, …, iz-th value from respective value sets of these sources. (It is also possible that the set of output values for an input combination is empty.)
An example:
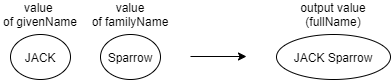
Metadata mapping
Here we have to start thinking of metadata.
We need to compute metadata for each of the output values produced. For simplification, we can assume that if a mapping produces more than one output value for a given combination of input values, all of them will get the same metadata. Therefore, we can restrict our thinking to metadata for single output value.
From the metadata point of view it is not important if the (data) values are being added or kept unmodified by the mapping. The only thing we look at is that we want to skip computing metadata for values that go into the output minus set. [1]
Metadata for given value are organized into items just like ordinary data in objects are. Standard data mappings reference their sources and target as items. It is natural for metadata mappings to do the same. In this way we could have partial mappings for (e.g.) level of assurance item, confidentiality item, creation time item, and so on. These mappings can be applied independently (and selectively, if needed), just like ordinary mappings are applied to data objects.
There are some differences, though.
-
While for standard data mapping we have exactly one input object, for metadata mappings we have multiple input metadata collections. For each input data value there is separate metadata. (Represented as a set of metadata items. Technically, metadata is represented by prism container value.)
-
At the metadata level we have no deltas. An input value (kept unchanged or being added) has its own metadata, and this metadata is immutable. It was attached to the value when the value was created, and will never be changed. (As the value itself does not change. It can be created or deleted, but never changed.) [2] [3]
Metadata mapping model
So, we have a situation where we combine input values a, b, …, z from sources SA, SB, …, SZ into
an output value. (For example, SA = givenName, SB = familyName, output = fullName).
A metadata mapping has sources and output just like ordinary data mapping. However, sources do not reference SA, SB, …, SZ. They are orthogonal to data mapping sources. Metadata mapping sources reference metadata items, like level of assurance, confidentiality, value origin, creation time, and so on. Each source corresponds to a single metadata item, just like mapping source corresponds to a single object item. Also, the output corresponds to a single metadata item; just like in mappings.
So, for example, our metadata mapping can have two sources: loa (level of assurance) and source (source system)
and one output loa (resulting level of assurance). The rule could be simple: take the lowest level of assurance
of all inputs. However, if source is socialLogin then override the computation and use loa of unknown.
(This example is weird. It is here only to demonstrate metadata mapping with two sources.)
<metadataMapping>
<source>
<path>loa</path>
</source>
<source>
<path>source</path>
</source>
<expression> ... </expression>
<target>
<path>loa</path>
</target>
</metadataMapping>
Example evaluation:
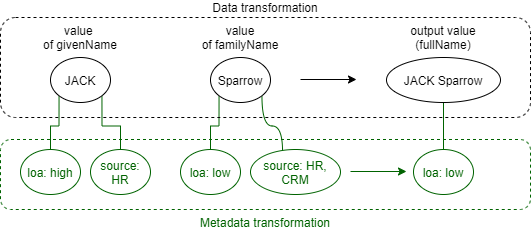
(Again, normally single familyName value would not have two sources. Here it has just for illustration purposes.)
Looking at metadata evaluation only:
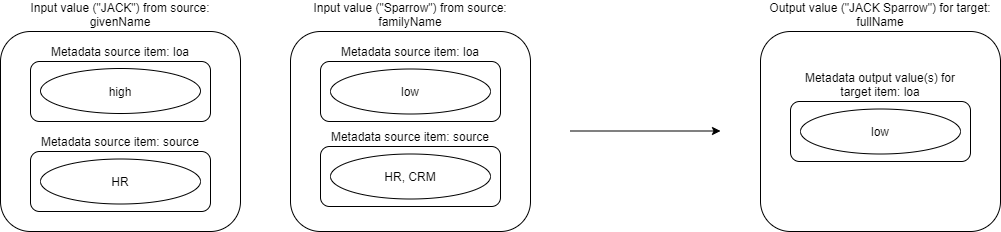
And, if we slightly generalize this picture, we get the following:
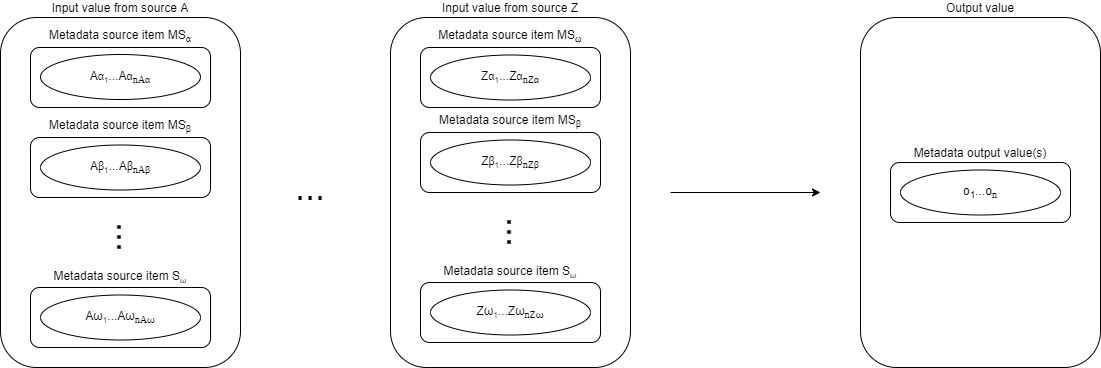
Note that sources are marked SA, SB, …, SZ, whereas metadata sources are orthogonal. For the lack of invention let’s mark them MSα, MSβ, …, MSω. Input values for metadata transformation are then given by the matrix (shown here as table):
| Data/metadata source | Source A | Source B | … | Source Z |
|---|---|---|---|---|
MS α |
Aα1, Aα2, … |
Bα1, Bα2, … |
… |
Zα1, Zα2, … |
MS β |
Aβ1, Aβ2, … |
Bβ1, Bβ2, … |
… |
Zβ1, Zβ2, … |
… |
… |
… |
… |
… |
MS ω |
Aω1, Aω2, … |
Bω1, Bω2, … |
… |
Zω1, Zω2, … |
Imagine we want to compute output values using a Groovy (or JavaScript, Python, etc.) script. What variables will the script expect?
General case (detailed information)
If the script would like to consider the whole situation, it would need to obtain the whole matrix. For example, it would need to know that
-
value of
JACKfor data sourcegivenNamehasloaofhighandsourceofHR, -
value of
Sparrowfor data sourcefamilyNamehasloaoflowandsourceofHRandCRM.
This information is simply accessible from the data values (JACK, Sparrow) if they are represented
as PrismValue objects - via valueMetadata() or similar method.
Simplified case (summarization on metadata source items)
However, often we want simply gather all values for specified metadata item and process them as set. Referring to our example, we would like to know that:
-
loa= {high,low} -
source= {HR,CRM}
The mapping would then look like this:
<expression>
<script>
<code>
source.contains('socialLogin') ? 'unknown' : custom.minLoa(loa)
</code>
</script>
</expression>
We assume that custom.minLoa is a function that takes a collection of LoA values
and returns the lowest one of them.
In the notation of Metadata-data source matrix we can define the variables as:
-
α = { Aα1, Aα2, … , Bα1, Bα2, …, Zα1, Zα2, … }
-
β = { Aβ1, Aβ2, … , Bβ1, Bβ2, …, Zβ1, Zβ2, … }
-
…
-
ω = { Aω1, Aω2, … , Bω1, Bω2, …, Zω1, Zω2, … }
for metadata sources α, β, …, ω.
Combinatorial evaluation?
Does it make sense to think about combinatorial evaluation of metadata values? I.e. something like:
-
JACK- loahigh- sourceHR- Sparrow - loalow- sourceHR→o1 -
JACK- loahigh- sourceHR- Sparrow - loalow- sourceCRM→o2
and then using o1 and o2 as a set of output values for resulting level of assurance?
Again, referring to Metadata-data source matrix we would create script inputs as:
-
Aα = AαiAα
-
Aβ = AβiAβ
-
…
-
Aω = AωiAω
-
Bα = BαiBα
-
Bβ = BβiBβ
-
…
-
Bω = BωiBω
-
…
-
Zα = ZαiZα
-
Zβ = ZβiZβ
-
…
-
Zω = ZωiZω
For all possible combinations of indices iAα, iAβ, …, iZω.
In our example, A = givenName with JACK value, B = familyName with Sparrow value,
α = loa, β = source, so
-
Aα (givenName/loa) ∈ {
high} -
Aβ (givenName/source) ∈ {
HR} -
Bα (familyName/loa) ∈ {
low} -
Bβ (familyName/source) ∈ {
HR,CRM}
So, is this important and worth implementing? Maybe. Let us just remember this option to eventually implement it when needed.
1. Even this is questionable. Consider e.g. assigned focus mappings for an assignment that is being deleted. We have to review such a situation eventually.
2. What about container value e.g. assignment modifications? Can we view that as value deletion and creation operations?
3. Also interesting is the following use case: Have information about provisioning targets for data. Know where the data are provisioned to or where they were provisioned in the past. This would probably require modifications of metadata in the opposite direction, i.e. going from outputs to source values.
Was this page helpful?
YES
NO
Thanks for your feedback