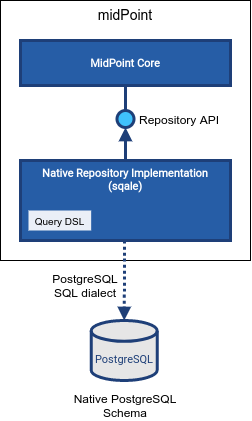
Native PostgreSQL Repository
|
Since 4.4
This functionality is available since version 4.4.
|
MidPoint stores its data in a relational database. The database of choice for midPoint is PostgreSQL, leading open source relational database. MidPoint contains implementation of data storage mechanisms (a.k.a. "repository") that tuned specifically for PostgreSQL database, taking advantage of PostgreSQL-specific features.
Please see the following pages for details:
- Usage
- PostgreSQL Configuration
- DB maintenance
- Migration to Native PostgreSQL Repository
- Design and Implementation
See Repository Configuration page for reference information about the configuration options.
|
Sqale
Native PostgreSQL repository implementation is nick-named "sqale" (read "scale") in midPoint source code.
The implementation can be found in repo-sqale component.
It was developed in midPoint 4.3 and 4.4 as a part of midScale project.
|
Besides this documentation, you can also review the webinar about the Native Repository (which is a bit longer as it goes quite in-depth) or the slides.
Compared to the Generic repository
This is just a short list of the main differences. Native repository:
-
supports only PostgreSQL database, but utilizes its features better;
-
scales better and produces more efficient SQL queries (does not use Hibernate ORM anymore);
-
uses PG inheritance for tables, e.g.
m_usernow contains all the columns, no JOINs needed; -
separate tables for various reference types (these are often joined, it should help);
-
serialized objects (
fullObject,delta) are stored as JSON by default (saves space) and compression options are not available (left for the DB); -
has some filter interpretation improvements, e.g. support for
NOT EXISTS, better multi-value support; the differences are mentioned in the midPoint Query document; -
uses subqueries (
EXISTS) instead ofJOIN, common cases whereDISTINCTwas previously necessary are extremly rare now; -
uses single iterative search method, is strictly sequential,
iterationMethodis ignored; -
extensions are stored in
JSONBcolumns inline with the rows; -
supports audit table partitioning;
-
finally, new repository requires that OIDs are correct UUIDs!
See also
-
Repository Database Support discusses old and new repository and our support strategy.
Was this page helpful?
YES
NO
Thanks for your feedback