Resource Schema Improvements in 4.6
Minutes from the design meetings.
27. 4. 2022
Conclusions So Far
-
We need to distinguish between inheriting from a resource template and "random" including a resource fragment. The former should be strictly limited to a single resource (potentially chained), while there can be more fragments.
-
We won’t implement those fragments yet. So, only inheritance from a "super-resource" (a.k.a. resource template) will be supported for now.
-
The merging policy would be: "merge everything you can". We can inspire by merging archetypes and GUI policies.
-
A flag "resource is abstract" will be added.
-
We’ll need to display the full (merged) configuration. If possible, also with an indication of who contributed what. This would be needed for GUI as well as in Studio.
-
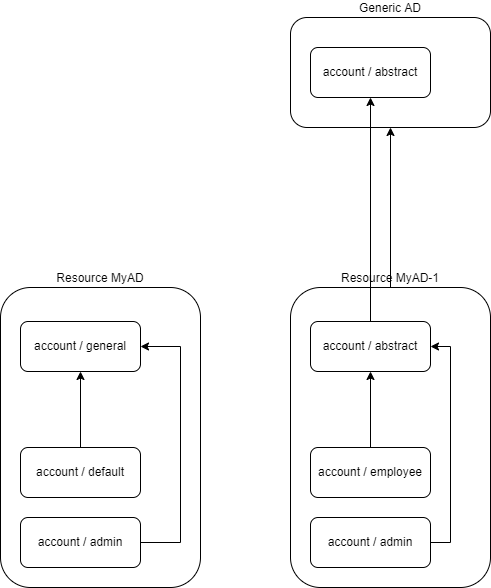
Object types are identified by their
kindandintent(both abstract and concrete ones). So the supertype will be referenced by itskindandintentas well. Supertypes with matchingkindandintentin super-resource will be inherited by default. (TODO what if both explicit and implicit supertypes are present?)
Other Interesting Ideas
-
We could create archetypes for resources like
source,target, aiding GUI in guiding the user e.g. by not offering outbound mappings for puresourceresources. Will these archetypes need to be auxiliary? If so, we may need to make structural archetype optional.
Timing: In a week there could be a basic version of the resource and object type inheritance available on master.
13. 4. 2022
Conclusions So Far
-
The
schemaHandlingandsynchronizationsections (i.e. resource object type definition and its synchronization definition) can be assumed to be 1:1. -
The
synchronizationsection will be split into constituent parts that will be put directly into the object type definition:-
correlation(currentlysynchronization/correlationDefinition) that specifies how the correlation is to be done, -
classificationthat delineates the set of resource objects covered by the particular object type (TODO a better name is to be found:objects?delineation?set?boundary? …)-
Instead of the current
condition, the preferred way how to specify the objects will bebaseContext(optional) withfilter(optional). This will allow using the specification not only to classify an existing shadow, but also to search for all shadows of the specific object type. (The existingconditionwill be retained for backwards compatibility and for extra complex situations.)
-
-
Other Interesting Ideas
These have got substantial but not definite level of agreement.
-
The
reactionspecification will be no longer bound to clockwork-based actions. We may specify things like "create a case" (correlation, data fixing, …), "link/unlink the owner quickly" (i.e. without involving), maybe "notify", "set policy situation", and so on. -
Idea for correlators: They could work with more implicit configuration, like setting some attributes as relevant for correlation. (E.g. marking
employeeNumberas the definite correlation property, andcnas a hint.) Individual correlators - when enabled - would look for this information, and automatically take them into account. E.g. filter-based correlator would concentrate onemployeeNumber, and ignorecn, while fuzzy correlator would consider both, with appropriate weights. -
Idea for mappings: They would no longer represent a transformation. Instead, a mapping will denote a relation between (e.g.) resource object attribute and focal object property. And this relation will be used for data transformation (inbound and/or outbound, with specified strength), for data comparison (~ preview mode?), for correlation, and so on. (Question: what about relations that are not 1:1?) Note: "boxed" mappings (built-in or custom-created ones) will provide support for all - or selected - of these uses.
-
Conditions in classification would be (maybe!) no longer required to be disjunctive. Maybe the missing condition should be interpreted as "if none of the others apply". Note that this could be a problem with the forward use of the conditions, i.e. when constructing resource object query to obtain all objects of given type.
-
It would be good to have an ability to specify different reactions based on the situation (e.g. on whether account is enabled or disabled).[1] Currently, it’s possible do to that using conditions. But maybe we’d need something more flexible (like an expression that would provide the reaction?)
-
Open question (in addition to ones presented in the invitation): How to validate account data before executing the synchronization? How to avoid synchronization of malformed accounts? This points to "shadow marking" functionality.
-
Another additional open question: When listing accounts with unfinished classification rules we may obtain a lot of misclassified shadows. There should be something to avoid this, or to clean up the mess simply and quickly.
-
It looks like the "private functionality" for types (see the intro presentation) may be a good idea; to avoid code duplication in mappings. However, Java code is maybe not realistically to be expected for the majority of engineers. Some useful tricks were suggested, e.g. auto-generating Groovy getters/setters from the extension schema.
-
Also, mapping chaining for inbounds might be relevant, to avoid duplication or the need to "M:N" mappings (multiple account attributes to multiple focus attributes).
1. We think that distinguishing such cases using
intent is a bit overkill. E.g. because of the need to re-classify after such changes.
Was this page helpful?
YES
NO
Thanks for your feedback