Performance Improvements in 4.8
|
Since 4.8
This functionality is available since version 4.8.
|
After optimizing the model-level post-processing of retrieved objects, we tried to measure the overall performance of midPoint. The semi-real performance test, developed as part of midScale project, was used.
Preliminary Results
The preliminary (indicative) results were obtained from the execution of the test on a dedicated iron, an older development PC. They may not be precise, as the number of objects involved was quite low (up to thousands), in order to gather the data quickly.
More detailed tests are being prepared. But let us present those preliminary results anyway.
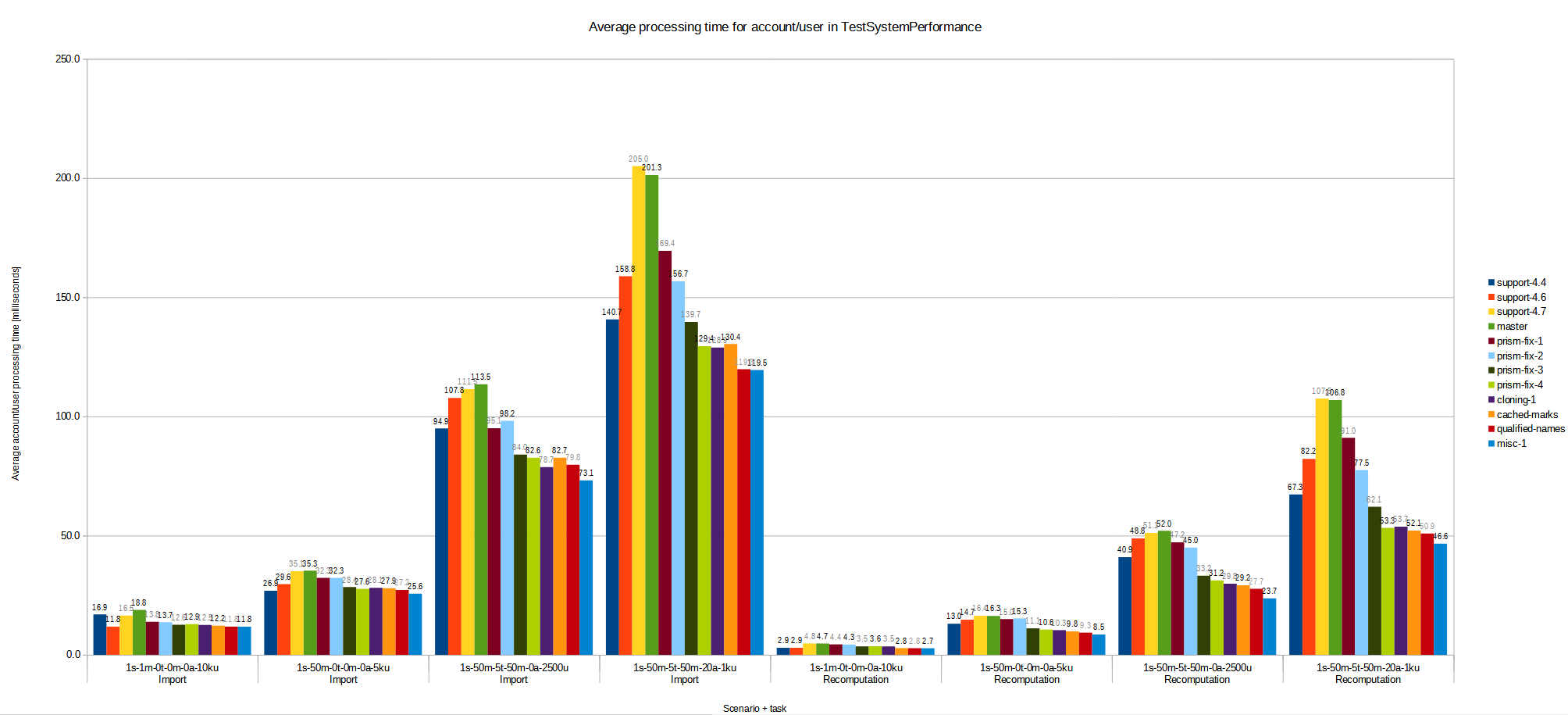
Figure 1. Preliminary performance results
The chart compares average processing time for an account (during "initial import" scenarios) and then for a user (during "recomputation" scenarios). Individual scenarios differ in the size and complexity of the simulated deployment:
| Scenario | Source systems | Source mappings | Target systems | Target mappings per system | Assignments per user | Number of accounts/users |
|---|---|---|---|---|---|---|
|
1 |
1 |
0 |
- |
0 |
10,000 |
|
1 |
50 |
0 |
- |
0 |
5,000 |
|
1 |
50 |
5 |
50 |
0 |
2,500 |
|
1 |
50 |
5 |
50 |
20 |
1,000 |
| Version | Source code | Comment |
|---|---|---|
|
Current on Apr 27, 2023 |
|
|
Current on Apr 27, 2023 |
|
|
Current on Apr 27, 2023 |
|
|
Current on Apr 27, 2023 |
|
|
midPoint the same, prism 531be184 |
Improved |
|
midPoint the same, prism 1d5f8911 |
Improved |
|
midPoint the same, prism e84729be |
Removed two iterative definition lookups. |
|
Not freezing already frozen objects. Skipping checking equivalent prism values during parsing from repo. |
|
|
midPoint f8e8d6b1 |
Reduced the number of object clone operations. The effect on the performance seems to be lower than expected. |
|
midPoint 0f2062df |
Enabled global caching of |
|
The presence of unqualified names in |
|
|
Improved XMLGregorianCalendar cloning,
avoided slow |
Details
Testing scripts
Listing 1: Example of testing script for 4.7
cd /home/pavol/mp47
export DB="-Dtest.config.file=test-config-new-repo.xml -Dmidpoint.repository.jdbcUrl=jdbc:postgresql://localhost:5432/midpoint-test-47 -Dmidpoint.repository.jdbcUsername=midpoint -Dmidpoint.repository.jdbcPassword=..."
/home/pavol/perf/tests.shListing 2: Common testing script
#!/bin/bash
export GIT_COMMIT=$(git rev-parse HEAD)
export BRANCH=$(git branch --show-current)
PREFIX="integration-test -pl :story -nsu -Pextratest -DenableAssertions=false -Dit.test=TestSystemPerformance $DB -Dsources.multi-attr-values=5 -DtaskTimeout=7200000 $EXTRA"
SOURCES_1_50="-Dsources.resources=1 -Dsources.single-mappings=50 -Dsources.multi-mappings=50"
SOURCES_3_50="-Dsources.resources=3 -Dsources.single-mappings=50 -Dsources.multi-mappings=50"
TARGETS_3_50="-Dtargets.resources=3 -Dtargets.single-mappings=50 -Dtargets.multi-mappings=50"
TARGETS_5_50="-Dtargets.resources=5 -Dtargets.single-mappings=50 -Dtargets.multi-mappings=50"
TARGETS_0="-Dtargets.resources=0"
ROLES_0="-Droles.business.count=0 -Droles.technical.count=0 -Droles.assignments.count=0 -Droles.inducements.count=0"
SCHEMA_10="-Dschema.single-valued-properties=10 -Dschema.multi-valued-properties=10"
SCHEMA_50="-Dschema.single-valued-properties=50 -Dschema.multi-valued-properties=50"
SCHEMA_100="-Dschema.single-valued-properties=100 -Dschema.multi-valued-properties=100"
SCHEMA_200="-Dschema.single-valued-properties=200 -Dschema.multi-valued-properties=200"
# Assuming 8x vCPU -> 6 threads
THREADS="-Dimport.threads=6 -Dimport.no-op-runs=0 -Dreconciliation.runs=0 -Drecomputation.threads=6"
# Scale (build variable)
S=5
#
# Group 1: Single source, increasing number of mappings: 1, 10, 50, 100, 200 (both single and multi)
#
PREFIX_G1="$PREFIX -Dsources.resources=1 $TARGETS_0 $ROLES_0 $THREADS"
mvn $CLEAN $PREFIX_G1 -Dsources.single-mappings=1 -Dsources.multi-mappings=1 $SCHEMA_10 -Dsources.accounts=$((2000*S))
#mvn $PREFIX_G1 -Dsources.single-mappings=10 -Dsources.multi-mappings=10 $SCHEMA_10 -Dsources.accounts=$((2000*S))
mvn $PREFIX_G1 -Dsources.single-mappings=50 -Dsources.multi-mappings=50 $SCHEMA_50 -Dsources.accounts=$((1000*S))
#mvn $PREFIX_G1 -Dsources.single-mappings=100 -Dsources.multi-mappings=100 $SCHEMA_100 -Dsources.accounts=$((1000*S))
#mvn $PREFIX_G1 -Dsources.single-mappings=200 -Dsources.multi-mappings=200 $SCHEMA_200 -Dsources.accounts=$((1000*S))
#
# Group 2: Increasing number of sources (having 50 + 50 mappings): 5, 10, 20
#
PREFIX_G2="$PREFIX -Dsources.single-mappings=50 -Dsources.multi-mappings=50 $SCHEMA_50 $TARGETS_0 $ROLES_0 $THREADS"
#mvn $PREFIX_G2 -Dsources.resources=3 -Dsources.accounts=$((500*S))
#mvn $PREFIX_G2 -Dsources.resources=5 -Dsources.accounts=$((500*S))
#mvn $PREFIX_G2 -Dsources.resources=10 -Dsources.accounts=$((500*S))
#
# Group 3: Increasing number of targets (having 1 source, 50 + 50 mappings): 5, 10, 20
#
PREFIX_G3="$PREFIX $SOURCES_1_50 $SCHEMA_50 $ROLES_0 $THREADS -Dtargets.single-mappings=50 -Dtargets.multi-mappings=50"
mvn $PREFIX_G3 -Dtargets.resources=5 -Dsources.accounts=$((500*S))
#mvn $PREFIX_G3 -Dtargets.resources=10 -Dsources.accounts=$((500*S))
#
# Group 4: Increasing number of assignments (having 1 source, 5 targets, 50 + 50 mappings; each BR has 2 TRs): 5, 10, 20, 100
#
PREFIX_G4="$PREFIX $SOURCES_1_50 $TARGETS_5_50 $SCHEMA_50 $THREADS -Droles.business.count=100 -Droles.technical.count=500 -Droles.inducements.count=2"
#mvn $PREFIX_G4 -Droles.assignments.count=5 -Dsources.accounts=$((250*S))
#mvn $PREFIX_G4 -Droles.assignments.count=10 -Dsources.accounts=$((200*S))
mvn $PREFIX_G4 -Droles.assignments.count=20 -Dsources.accounts=$((200*S))
#mvn $PREFIX_G4 -Droles.assignments.count=100 -Dsources.accounts=$((100*S))
#
# Group 5: Misc
#
PREFIX_G5="$PREFIX $SOURCES_3_50 $TARGETS_3_50 $SCHEMA_50 $THREADS -Droles.business.count=100 -Droles.technical.count=500 -Droles.inducements.count=2"
#mvn $PREFIX_G5 -Droles.assignments.count=50 -Dsources.accounts=$((150*S))The -DenableAssertions=false turns off the evaluation of Java assertion statements.
Was this page helpful?
YES
NO
Thanks for your feedback