Mapping definition
[x] Use reasonable defaultsSolution Notes (from First Steps)
- Solution Ideas
- Missing Features
- Correlation: Candidate Identifier
- [DONE 4.7, being improved] User-friendly Resource Wizard
- [DONE, 4.7] Shadow Marks
- Custom Activation Status Override
- TODO New mapping mode/strength
- (Not sure yet) Password Expiration
- [DONE, 4.7] Import (single account) from resource - simulation/preview only
- (Not sure yet) Links in Approvals Notifications
- [DONE, 4.6] Simple Assignment Of Archetype (Inbound)
- User-Friendly Schema Docs
- Value Override
- [considering DONE? - simulations, 4.7] Mapping Preview/Warnings
- Safe and Clean Removal of Resource
- [DONE, 4.7] Simple Resource Wizard
- Simple Connector Management
- User-Friendly Bulk Task Generator in GUI
- Correlation-Only Mappings
- Conditions for Items Correlators
- Schema Improvements
- New Pre-Defined Objects
- TODO For Discussion
- Things To Work On
Moved from First steps here for possible future use.
Solution Ideas
Unstructured notes. Move to other parts/documents as necessary.
-
Allow direct access to database (PostgreSQL only, read-only, with upgradeability disclaimers). This may help to address unforeseen use-cases, with technology/toolset that the engineers already know (SQL). The risk to upgradeability is relatively low, as we have to keep DB data model (mostly) backwards-compatible anyway.
-
Improved default configuration: pre-configure midPoint for the usual use-cases. How exactly? Better samples? Pre-configured profiles?
-
Resource mappings-related: we can prepare function libraries (see also below) with most-common code usable for mappings. Admin will simply select one of the functions. New function can be added any time.
-
-
Improved user experience: How exactly? For who? Engineers? End users? How skilled? What use-cases?
-
Improved documentation: how exactly? What documentation? For who? Which format? text? video?
-
"Complexity spectrum" approach:
Simple and common tasks should be very easy to do (few click in GUI).
Medium-complexity and less-common tasks should still be relatively easy (still GUI, but may be more click and complex forms/flows, even writing one-liner expression, but still in GUI).
Complex and uncommon tasks may need deeper expertise/experience (e.g. editing JSON/XML).
Exotic tasks should still be possible, but may require programming (e.g. complex scripts, plugins, Maven overlay, etc.).
This approach was there since the beginning of midPoint, it is one of the design principles. Yet, it may not be well documented, and it might have been neglected sometime. -
From scientific to engineering approach:
MidPoint attribute mappings will be by default: (*) Tolerant Other values of single-value attributes are permitted Other values of multi-value attributes are permitted ( ) Enforcing Other values of single-value attributes are not permitted (midPoint overwrites such values) Other values of multi-value attributes are not permitted (midPoint removes such values) MidPoint group membership mappings will be by default: (*) Tolerant Group membership managed by other means is permitted and tolerated ( ) Enforcing Group membership managed by other means is not permitted (midPoint removes such values) -
Complete automation vs Human task automation: Do we want midPoint to do everything automatically (read from HR, process policies, create accounts). Or do we want midPoint to manage people that do it manually (review HR data, approve requests, create tickets for admins to create accounts)? We probably want both, but to what degree? What we will be recommending? (methodology)
Current brainstormings: 5-6/2022
| This are preliminary steps of Connect/Cleanup/Automate which are currently brainstormed. Hic sunt dracones. |
Step I: Connect
Connect Source System (HR)
-
Go to Resources, New resource (no template for HR), Wizard #1 (Resource Connection Wizard?) starts
-
Enter basic connection parameters
-
midPoint will try connection and return further configuration properties (in case of LDAP this would be
baseContextetc.) -
Schema restrictions (generation constraints) - for HR probably not, accounts only
-
Save resource, no mappings yet
-
I may now list the accounts in the resource through midPoint to see which data I have
-
Click This looks good, I want to import data, Wizard #2 (Resource Mapping Wizard?) starts
-
Edit correlation criteria (which attribute should correlate to which property)
-
Set
focusTypefor synchronization (default:UserType) -
TODO we don’t set specific kind/intent here, what about 4.6 ?
-
TODO TODO what about reference to archetype to be assigned here?
-
Set situations and reactions
-
UNMATCHED: reasonable default for source system isaddFocus -
UNLINKED: reasonable default islink -
LINKED: "synchronize=true" equivalent -
DELETED: reasonable default has to be set by the user:-
no reaction: if account cannot be deleted from source system
-
unlink: if account can be deleted, but we do not want to do anything -
inactivateFocus: if account can be deleted and we want to disable midPoint user -
deleteFocus: if account can be deleted and we want to delete midPoint user
-
-
DISPUTED: ? can happen with source at all?
-
Start import user phase (repeat until satisfied)
-
Edit or improve mappings (
givenName,familyNameetc, TODOlifecycleState; no mapping fornameyet) - strong mappings-
All mappings are either
asIsor simple mappings using library (trim, upper/lower case, …)
-
-
import from source system (HR) - all users or first X accounts
-
Enable
fullNamemapping - in either:-
in global object template (there will be already one global object template (part of initial objects), but no enabled mappings by default
-
(TODO 29/04/2022 alternative: one default archetype e.g.
Personwhich has its own template. The archetype must be assigned to user, e.g. in synchronization settings just like FocusType, see above)
-
| TODO we have not set any attribute for correlation criteria. Based on discussion it’s not "mandatory" for simple cases (no multi-accounts)… |
| FYI: We have imported HR data; we do not have usernames yet. |
Connect target system (AD)
-
Create resource using predefined template
-
We assume we want to set
$focus/namefrom the AD/LDAP, but not from all other target resources.If we do not want username from AD/LDAP, we might already have it from HR (e.g. employee number). So this should be optional / to be selected by the user.
-
outbound mappings are in "comparison" mode by default
-
non-invasive configuration (no reactions for situations, not even
UNLINKED→link) -
save resource
-
list accounts via midPoint (to check connection to resource, permissions of midPoint service account etc.)
Step II: Clean up
Correlation phase (repeat until satisfied)
-
review/update correlation. Select the attributes to correlate and how. Select from attributes which have mappings, and how (equal, substring, …). Some weight/negative conditions. (E.g. if this attribute vs user property differs, this can’t match even if
ri:cnmatched$focus/fullName)."Smart correlation" based on attributes and their weight is also possible.
TODO this is important for Katka for Resource wizard
-
run reconciliation with target system (no dry-run - that will be eventually deprecated); because all reactions are non-invasive and mappings in "comparison mode" do not enforce anything yet.
FYI: Shadows are created in repository. -
run interactive reconciliation report to show situations/reactions - including situations
UNMATCHEDetc. for which we do not have any reaction - yet.FYI: Shadows are classified, situations are set. -
The report must show also "candidate" user owners.
NOTE: There is no
linkRefyet in the user! Should we store candidate owner(s) in Shadow? Should we consider this temporary and overwrite each time we run reconciliation? -
Report should show user identifier as a separate column and another column "display name" (typically
fullName) - this should be configurable using expressions. A’laadminGuiConfiguration?
-
(Optional) Account marking phase
-
mark unmatched accounts for later decommissioning if necessary. (We are not sure if we can decommission them immediately. Let’s postpone the decision. It will be visible in reports to differentiate unmatched from unmatched+this flag.)
-
mark unmatched or other accounts (linkable, but maybe some special) for later review ("do not update"), if we do not know what to do with them at the moment. It will be visible in reports to have a track of them.
-
mark protected accounts (in addition to using
<protected>element in resource). This will be visible in reports to have a track of them. (TODO: we should see also the accounts which are made protected using the old-fashioned way - they should be marked in shadows objects too!)-
NOTE: if the account has situation, setting it to
PROTECTEDwill erase it from Shadow. -
NOTE: some accounts may be also deleted directly by AD administrators after they see the report
-
Link accounts phase
-
manually link
UNMATCHEDandDISPUTEDaccounts to their owners if correlation was not successful (e.g. married women with different family names on both sides etc.) -
set reactions for
UNLINKED→linkandLINKED→ synchronize.Keep
UNMATCHED,DELETEDandDISPUTEDwithout any reaction.FYI: Most accounts are now in UNLINKEDandLINKED(the manually linked accounts) situation. -
run reconciliation again to link the accounts to midPoint owners
-
manually correlate
DISPUTEDaccounts using interactive owner selection from candidate owners (human interaction using cases)
FYI: All linkable accounts are in LINKED situation or in progress of manual correlation.
|
Username import phase if this is the resource to import username from (repeat until satisfied)
If we want to import existing usernames from this resource (e.g. AD), we need to do it for all LINKED accounts, including the accounts marked for later review ("do not update").
-
Prepare/uncomment/activate (weak?) inbound mapping from target to midPoint user (mapping is default in the bundled resource template) E.g. from
userPrincipalNameminus@domain.comto$focus/name. -
Preview the inbound username mapping on single user before running reconciliation
-
Prepare also outbound mapping for the attribute (still in "comparison" mode) to allow accounts to be created when midPoint starts to provision them in this target system.
-
Run reconciliation with the target system to import the usernames. Outbound mappings are still in "comparison" mode.
-
TODO maybe that inbound should be removed later in Automate phase (already noted there)? When? Or we just make the mapping strength
weakas we do not have any value yet in midPoint users and we will always have the value in the future! (But this will work only once.)
| FYI: Now we have all existing AD usernames in midPoint, we can consider the identifier unique. |
Attribute correlation phase (repeat until satisfied)
-
run reconciliation report on attribute level (simulation using mappings in "comparison" mode): what will midPoint change in target system (simulation of what would be done). This makes sense after the existing accounts are linked.
Review the report output with target system administrators.
The report should show some summary and changes e.g.:
-
How many accounts would be created, changed, deleted
-
How many accounts are marked "decommissioned", "to be reviewed", "protected" etc. (outbounds are ignored for them)
-
Which attributes will be changed and how many changes (e.g. attribute
givenNamewill be changed in 200 accounts; attributednwill be changed in 20 accounts), sorted descending -
Table of changes to be made (TODO how to present it? Our delta format e.g. in Preview changes takes too many screen space, how to even export it to CSV/Excel?)
-
-
based on the review, you have several options:
-
(Option 1) Update mappings in target resource (still in comparison mode), if they are incorrect
-
(Option 2) Mark more accounts for later processing (do not touch until that) to make exception
-
(Option 3) Let midPoint perform the account update(s) if the mappings are OK, even if they attempt to change target system accounts
-
Clean-up marked shadows
| FYI Shadows are still marked as decommissioned/do not update. |
-
Cleanup at least some marked shadows (decommissioned/do not update). TODO does this need mappings? This is the following action in the list
-
(Optional) Unmark "to be decommissioned" accounts (which are also UNMATCHED) to allow midPoint to eventually remove them in later phases.
-
(Optional) Run explicit action to delete accounts marked as "to be decommissioned".
-
(Optional) Unmark "to be reviewed" accounts to allow midPoint to update them in later phases.
-
Turn on the provisioning policy
-
(Optional) Run the simulation report one more time
-
Turn off the "comparison" mode in outbound mappings.
(midPoint is still not synchronizing changes from source)
-
Run reconciliation with target system to let midPoint do the desired changes.
| FYI: Accounts are now updated in target system based on mappings, except the accounts that are still marked. |
TODO TODO add correlation to HR
TODO TODO TODO somewhere here add correlation to HR?
Step III: Automate
Activate username generator
-
Edit default object template for users TODO or archetype(s)
-
Define mapping for
nameusing pre-defined expressions (select from list) - similar to mapping expressions in resource wizard -
The mapping must be strength=weak to avoid overwriting usernames imported from AD/LDAP
-
Example:
givenName initial + familyName + XXwhere XX is a number starting from 1, 2, up to 99 and the first available is used -
Example:
givenName initial + familyName + XXwhere XX is a number starting from 01, 02, up to 99 and the first available is used
-
-
All future midPoint usernames will be generated using this algorithm, starting with the lowest possible number which is not already used.
-
Turn off the (weak) username mapping from AD/LDAP to midPoint
Username exceptions and customizations
If your environment is using usernames which are not present in the target system used for username import (e.g. AD/LDAP) but are used in other systems, midPoint will be unaware of them until that system is integrated with midPoint. Account creation in such systems will fail if the account already exists.
In such case, you have the following options:
-
Connect the other system and import usernames from the system as well
-
Use a different username format for new users and accounts created by midPoint, e.g.
givenName initial + familyName + XXXwhereXXXis a number starting from 001, 003, up to 999 and first available is used. -
Resolve the situation when conflict happens by selecting a different username for the user, renaming user’s accounts using the new username and informing the user.
Define policy for automatic assignments
The first policy will be defined in Archetype, which is assigned to user while imported from source system.
-
Administrator can edit the policy (inducements) in midPoint GUI:
-
Edit archetype
-
Add inducement for target system (e.g. AD/LDAP)
-
Kind, intent are optional; not needed for the first iteration (TODO check for midPoint 4.6+)
-
-
-
In later iterations, roles or role-like objects and conditions for their automatic assignments can be added. This will require the administrator to update either Archetype or Object template or use role autoassignment feature.
-
TODO this policy must also define what to do when users are leaving!
-
-
We need to recompute users after we change anything in this policy!
Turn off the current provisioning to target system
-
Turn off the current provisioning to the target system for accounts
-
EXCEPT access right assignment, until we cover them via role-like objects in midPoint!!! Leave this for later iterations.
Turn on synchronization between HR and midPoint
-
Turn on the automatic synchronization between HR and midPoint by creating either Live synchronization or reconciliation task for HR resource accounts.
| FYI: From now on, all people from HR will get AD accounts |
Turn on automatic reactions for unauthoritative changes in target system
-
Set appropriate reactions for
UNMATCHED/DELETEDfor target system -
Schedule reconciliation task for target system
-
(Optional) Schedule reconciliation report to be generated/sent
How to connect HR to midPoint
-
Go to
-
Select the connector: either CSV or DatabaseTable connector
-
Configure the connection (CSV file path etc. or database connection)
-
Test the connection
-
Configure Schema/schema handling part using "drag&drop" to indicate:
-
which resource account attribute should correspond to which midPoint user attribute
-
left side: midPoint attributes
-
right side: resource attributes
-
dragging from left → right: outbound
-
dragging from right → left: inbound
-
-
indicate (e.g. bold, background color etc.) which attribute(s) is (are) used for naming convention in midPoint (
name,candidateUserNameetc.) in the list of attributes -
how is the value transformed (default: as is)
-
other options accessible as a predefined list of options (functions of functional library referenced from the resource configuration)
-
example:
Lowercase attribute value
-
-
-
Configure correlation: which resource account attribute should correspond to which midPoint user attribute for unique match
-
Save the resource
-
Edit the resource
-
List resource accounts
-
Import a single resource account with simulation option to see how the user would be created. Confirm the import or go back to resource configuration if needed.
-
Import accounts from resource
Import all "accounts" (records) from the HR resource, both active and inactive ones. Use lifecycle states to distinguish between active and inactive users.
The Import step can be repeated several times to iteratively fix the content in midPoint. If correlation configuration is changed during the iterations, the existing midPoint data may need to be purged (shadows) using the feature Delete all identities (NEW FEATURE REQUIRED: put this somewhere in resource configuration with proper warning/confirmation)
midPoint is now filled with authoritative data from HR.
How to connect target (AD) to midPoint
Assumption: AD resource would be already pre-configured (except the connection parameters).
-
Go to
-
Edit
ADresource -
Configure connection (AD parameters - as few as possible, use defaults for everything else)
-
Test connection
-
Review schema/schema handling configuration. If changes are needed, use "drag&drop" to indicate:
-
which resource account attribute should correspond to which midPoint user attribute
-
left side: midPoint attributes
-
right side: resource attributes
-
dragging from left → right: outbound
-
dragging from right → left: inbound
-
-
indicate (e.g. bold, background color etc.) which attribute(s) is (are) used for naming convention in midPoint (
name,candidateUserNameetc.) in the list of attributes -
how is the value transformed:
-
cn: default: as is -
sn: default: as is -
givenName: default: as is -
userPrincipalName: default: TODO -
dn: default: predefined function from functional library referenced from the resource configuration, example:Generate Distinguished Name from Given Name and Family Name)-
other options accessible as a predefined list of options (functions of functional library referenced from the resource configuration)
-
example:
Lowercase attribute value -
example:
DN with cn=GivenName FamilyName -
when selecting a function from the list, description and example should be displayed
-
-
-
-
Review Correlation / confirmation / identity matching step
-
preconfigured, e.g.
userPrincipalNameequals midPointextension/candidateUserNameoremployeeNumberequalsemployeeNumber -
possibly preconfigured for "reverse identity matching" by selecting which attribute mappings should match the existing resource values (e.g.
cn,snandgivenName) -
mapping "guessing" based on correlation:
-
midPoint will compare e.g. 50 users and 50 accounts to see if the correlation expression matches
-
mappings for simple cases can be derived from these matches
-
midPoint can make sure the mappings are OK as configured (that they provide the same values as there are on resource already)
-
-
-
Save resource
-
Run reconciliation (no outbound mappings activated yet)
-
Run reconciliation report / review accounts using midPoint
-
Mark accounts which cannot be processed correctly at the moment. The marking must be displayed in the reconciliation report.
The Reconciliation / reconciliation report steps can be repeated several times to iteratively fix the content in midPoint.
Correlation vs Mapping Guessing Mode
| Rough idea… |
If we have a known user (list of users) in midPoint and their corresponding account(s), we can let midPoint to guess either the correlation or the mappings.
Guessing correlation:
-
specify user in midPoint
-
specify account in AD (which we assume to be owned by this user, but is not linked to that user in midPoint yet)
-
midPoint will check if there is one or more attributes that could be used for matching (ideally: 1:1)
Guessing mappings:
-
specify user in midPoint which is already linked to his/her AD account
-
midPoint will check which mappings can be created from this user/account information - which user attributes vs which account attribute
-
asIsmappings, possibly some simple upper/lowercase mappings
-
Reporting Notes
We need the following types of report:
-
What is in target system and is not in midPoint? This allows detection of orphaned accounts, system accounts etc. This is more or less a reconciliation report.
-
What is in midPoint but not in target system? This allows detection of missing rules between midPoint and target system, e.g. missing conditions for automatic provisioning for certain populations etc. This is more or less a simulation report.
-
TODO but we won’t have any automatic provisioning at the beginning. No automatic rules yet. But we might have archetypes with inducements. ? This report may be more relevant for later phases…?
-
-
What will midPoint change in the target system? This allows detection of incorrect/missing mappings between midPoint and target system as well as between midPoint and source system. This is more or less a simulation report but beyond the current implementation of thresholds. We need to preview the changes.
And perhaps this one which is similar to "What will midPoint change in the target system?":
-
What has this task done? The information about what has just happened is certainly in audit log and if there are any errors they can be stored either in the task itself or in the processed objects. But we lack "one button away" way of showing it - we need to show information which this task run has collected. We could re-use the same report (or its look) which we use for simulation, but this time we will show what has happened. Summary of actions, summary of attribute changes (e.g. DN was changed in 100 accounts etc.) and the changes and results from audit log…
For all reports: how to execute actions (manual correlation etc.) from the reports? Using interactive pages a’la ?
What is in target system (AD) and is not in midPoint?
Implementation in midPoint: target system reconciliation + reconciliation report. The report can display information about the last reconciliation for the system and can confirm tha user wants to run the reconciliation now - before the report. (Or vice-versa, confirm that user is OK with the last reconciliation timestamp.)
The report (ideally interactive in Resource/Accounts, exportable to Excel) should contain the following information:
Query:
-
just like reconciliation report (working with Shadows of certain resource)
Columns:
-
Account identifier (TODO which one in case of AD?
dnoruserPrincipalName?) -
Account status
-
Account mark
-
Situation
-
(with some tooltip/help for administrators about meaning)
-
(display also what would happen if this is not dry-run!!! e.g. account would be deleted (situations/reactions)
-
-
TODO what about identity matching? Some kind of probability…? And reason?
-
TODO if situation is
DISPUTED, we could perhaps indicate potencial owners in the report? -
TODO if situation is
DISPUTED, Change owner action should perhaps use the potential owners instead of showing all users in midPoint?
-
-
Intent TODO may be confusing for beginners!
-
Owner
-
TODO we probably also need: Owner display name
-
Candidate owner (in case we have dry-run) (TODO maybe also indicate why it was matched?)
-
TODO we probably also need: Candidate owner display name
-
Maybe rename
OwnertoMatched userorMidPoint Useror something like that…
-
-
Pending operations TODO not necessarily needed for this case - read-only reconciliation
-
Status of the owner/candidate owner (probably part of the values of owner/candidate owner? bad to parse in CSV then…)
TODO how to display multiple potential owners in single cell or even two cells next to each other, if we use Candidate owner and Candidate owner display name? Table in table??? How is this done in ID Match?
| Account identifier TODO which one in AD? | Status | Mark | Situation | Owner | Owner display name | Candidate owner | Candidate owner display name |
|---|---|---|---|---|---|---|---|
enabled |
DECOMMISSION |
UNMATCHED (tooltip: Account in target system without owner in midPoint) |
(none) |
(none) |
(none) |
(none) |
|
enabled |
(none) |
UNLINKED (tooltip: Account in target system with candidate owner in midPoint) |
(none) |
(none) |
jdoe (disabled) |
John Doe |
|
enabled |
(none) |
LINKED (tooltip: Account in target system owned by midPoint user) |
jsmith24 (enabled) |
John Smith |
(none) |
(none) |
|
enabled |
DECIDE-LATER |
DISPUTED (tooltip: Account cannot be correlated to one midPoint user) |
(none) |
(none) |
jsmith2, (enabled) - 33% jsmith7, (enabled) - 33% jsmith98, (disabled) - 33% |
John Smith Joe Smith Jack Smith |
Visualisation notes:
-
TODO: Either use Repository or Resource view, but do not confuse user. If we use passive caching…?
-
Search: ability to hide rows based on at least
SITUATION,protectedbut not only that -
Ability to export the (interactive) view to Excel for further processing outside midPoint
-
Top part of report ("summary panel"):
-
Show some kind of "pie graph" or something similar to graphically represent the state to see how optimistic/pesimistic the situation is.
-
The colors for situations
UNMATCHED,DISPUTED(possibly others) can be emphasized to indicate problems or need for decisions. -
Percentages of
UNMATCHED,DISPUTED(possibly others) can help to distinguish if the problem is caused by correlation misconfiguration (manyUNMATCHED) or data quality issues (manyDISPUTED). Some suggestions based on this may be displayed. -
Display if this is a result of dry-run (? TODO ?)
-
Display how was the correlation done (maybe descriptions from correlation settings, identity matching etc.). Human-readable! Maybe Axiom query, but not sure about it…
-
-
Protected accounts part:
-
List of accounts that are currently protected. If there are none, maybe we should indicate this too, as we usually need some protected accounts anyway.
-
-
List of accounts part:
-
see the notes for Columns above
-
What is in midPoint and is not in target system (AD)?
| This report should be executed after the reconciliation to have information about existing state. |
| This report might be actually implemented as part of "What will midPoint change in target system (AD)?". "Add" might be also considered as a change… |
TODO Implementation in midPoint: ? recomputation with "output" limited to target system (AD) with simulation mode ? Special mapping mode? It seems to be similar to the simulation of changes which midPoint is about to make.
The report (ideally interactive in Resource/Accounts, exportable to Excel) should contain the following information:
Query: ? TODO ? focus oriented
Columns:
-
User name
-
User Full name (or Given Name and Family Name)
-
User status (
activation/effectiveStatusor something else?)-
This can help to diagnose issue when disabled users would be provisioned to AD
-
-
Target system account that would be created (identifier)
| User name | Full name | User status | Account identifier to be created |
|---|---|---|---|
jdoe |
John Doe |
Disabled |
jdoe |
jsmith |
John Smith |
Enabled |
jsmith |
Visualisation notes:
-
Search: filter uses as supported by standard user listing + ability to hide rows which are "OK"
-
Ability to export the (interactive) view to Excel for further processing outside midPoint
-
Top part of report ("summary panel"):
-
How many accounts are missing (at least what midPoint thinks) and will be created (add operation)
-
Display information that this is a simulation (? TODO ?)
-
-
List of users:
-
see the notes for Columns above
-
What will midPoint change in target system (AD)?
| This report should be executed after the reconciliation to have information about existing state. |
TODO Implementation in midPoint: ? reconciliation or recomputation limited to target system (AD) with simulation mode ?
TODO Or could this perhaps use passive caching (reconciliation will be executed before this report anyway)?
The report (ideally interactive in Resource/Accounts, exportable to Excel) should contain the following information:
-
just like reconciliation report (working with Shadows of certain resource)
Columns:
-
Account identifier (TODO which one in case of AD?
dnoruserPrincipalName?) -
Account status
-
Account mark
-
Situation
-
(with some tooltip/help for administrators about meaning)
-
(display also what would happen if this is not dry-run!!! e.g. account would be deleted (situations/reactions)
-
-
TODO what about identity matching? Some kind of probability…? And reason?
-
TODO if situation is
DISPUTED, we could perhaps indicate potential owners in the report? -
TODO if situation is
DISPUTED, Change owner action should perhaps use the potential owners instead of showing all users in midPoint?
-
-
Intent TODO may be confusing for beginners!
-
Owner
-
Candidate owner (in case we have dry-run) (TODO maybe also indicate why it was matched?)
-
TODO We probably need also Candidate owner display name
-
Maybe rename
OwnertoMatched userorMidPoint Useror something like that…
-
-
Pending operations TODO not necessarily needed for this case - read-only reconciliation
-
Status of the owner/candidate owner (probably part of the values of owner/candidate owner)
| Account identifier TODO which one in AD? | Status | Mark | Situation | Owner | Owner status | Change type | Number of changed attributes | Change |
|---|---|---|---|---|---|---|---|---|
enabled |
LINKED (tooltip: Account owned by midPoint user) |
John Smith |
enabled |
Update |
1 |
> Family name |
||
enabled |
LINKED (tooltip: Account owned by midPoint user) |
Jeremiah Smith |
enabled |
Update |
1 |
> Distinguished Name |
||
enabled |
REVIEW_LATER |
LINKED (tooltip: Account owned by midPoint user) |
Jebediah Smith |
enabled |
Update |
4 |
> Distinguished Name > Family Name + Member Of > Description |
Legend (example):
-
>: attribute value to be replaced (single-value attribute)
-
+: attribute value to be added (multi-value attribute, e.g. groups)
-
-: attribute value to be removed (multi-value attribute, e.g. groups)
-
Maybe we could show at most X changes, to display more, administrator could "zoom in" by clicking. (Would need to be interactive report.)
-
We should display even the values, but that would require multiple "zoom in". (Would need to be interactive report.)
-
Example of zoomed info for specific user from the above table:
-
Account identifier: jsmith4@example.com
-
Status: enabled
-
Mark: REVIEW_LATER
-
Situation: LINKED (Account owned by midPoint user)
-
Owner: Jebediah Smith
-
Owner status: enabled
-
Change status: Update (Account will be updated by midPoint) but the operation will be ignored due to REVIEW_LATER marking.
| Attribute | Old value | New value |
|---|---|---|
Distinguished name |
cn=Jebediah sMith,ou=. . . |
cn=Jebediah Smith,ou= . . . |
Family Name |
sMith |
Smith |
Description |
ticket 1234 |
ticket 0938 |
Member Of |
|
|
Some kind of statistics, which account attributes are being added/deleted/changed to see the trends, example:
| Attribute | Number of changes |
|---|---|
Distinguished Name |
109 |
Family Name |
109 |
Account status |
80 |
Member of |
75 |
Description |
10 |
TODO would it be possible to click the list of changes and preview the changes related for the attribute/resource for all affected accounts? Interactively.
The reports should be interactive and allow operations - e.g. mark the account.
Visualisation notes:
-
Top part of report ("summary panel"):
-
How many accounts will be updated and will be created (modify operation)
-
Which attributes (statistics) are to be updated most? We want to see the trends to diagnose possible problems in mappings.
-
Display information that this is a simulation (? TODO ?)
-
-
List of users:
-
see the notes for Columns above
-
| The two reports for showing what midPoint would create and update can be also merged to one. In that case some summary panel with statistics (no changes / additions / removals / updates) would be nice in report "summary panel". |
Archetypes
We should assign Person structural archetype to all users that we import from HR.
Additional auxiliary archetypes (Employee, Contractor, Student) can be also assigned.
However, we want these archetypes to be auxiliary, as a person may be an employee and a student at the same time.
Notifications
TODO maybe more
Password expiration
We do not have password expiration notification at all. To be more precise, we do not have a process checking the passwords to be expired soon. There should be a process + notification to the user’s e-mail address some (preconfigured) time before the password is expired as user cannot log in to midPoint with expired password.
The e-mail should contain a link to midPoint.
TODO User expiration
If user is created with validTo, there should be a process + notification to the user’s e-mail address some (preconfigured) time before the user is expired.
TODO: user’s manager instead of user?
TODO: what should user do?
Approvals / Manual provisioning / Identity Matching?
We have notifications (at least for approvals, did not check Manual provisioning) for actors, but the defaults are too technical. (Mentioning process instance etc.)
We should embed information about previous steps in multi-stage environment.
Work item allocations need to embed a link to midPoint to act upon the work item.
TODO: consider using HTML (tables and images).
Add/Modify/Delete events notifications
We have notifications, but the defaults are too technical.
What could help is to print the information about properties/attributes in tables and make sure we are using Display names everywhere.
TODO: what about assignments and their parameters?
Password reset
We can re-use the functionality we have. Link for password reset will be sent to user’s e-mail
Lifecycle
Keeping Old Identities
We want to keep "old" identities in midPoint. Motivation:
-
we want to avoid identifier reuse.
-
we want to revive old accounts of users that are returning to the system (e.g. former employees).
-
we want to clearly see accounts that belong to former employees, to clearly see who is (was) the owner.
Therefore, we would like to import both active and inactive identities from HR.
We are going to distinguish them using lifecycleState.
Lifecycle States
| State | Description | Accounts | Assignments | Archetype | Notes |
|---|---|---|---|---|---|
Proposed |
Users that are being prepared for on-boarding. E.g. employees that will start working next month. |
existing, disabled |
present, active |
present, active |
We want accounts to exists, e.g. for mailbox to exist, so the new employee can receive instructions for their first days at work. Alternatively, maybe we want accounts to exist (which requires active assignments), but no project/org/group membership yet (which requires inactive assignments). What to do about it? |
Active |
Normal, active users. E.g. active employees. |
existing, enabled |
present, active |
present, active |
|
Suspended |
User that we still have an active relation with, however the relation is temporarily suspended. E.g. leave of absence, such as maternal leave or sabbatical. Also, project which is on hold, role undergoing urgent security review, device marked as "forgotten at home" or "in repair", etc. |
existing, disabled |
present, inactive |
present, active |
We want to keep accounts and assignments, to make sure we can easily "resume" the user. It is very likely that the user will be re-activated eventually. Question: do we want this user to be shown as part of a team or orgunit? |
Inactive |
Former user, no longer active. E.g. employee that left recently. Also, recently-finished project, decommissioned role, device marked as "lost", etc. |
existing, disabled |
present, inactive |
present, active |
We want to keep accounts and assignments. In case that a mistake was made and the employee was "fired" by mistake, it will be easy to re-activate the accounts and re-provision privileges. No (important) information should be lost. It is very unlikely that a user in this state will be re-activated (however, it may happen). The HR data record (account) will probably still exist in this state. We would like to keep user in this state for some time (months, years).
Then automatically transition to This is not well aligned with |
Archived |
Very old users, almost forgotten. E.g. employees that left years ago. |
non-existent (except for resources that do not support delete) |
not present (deleted when entering this state) |
not present (deleted when entering this state) |
The purpose of this state is mostly to avoid identifier reuse. In some cases also as a data archive used to interpret OIDs in audit logs. Entering to this state will be probably triggered by two events: 1. HR account deleted, 2. rotting in We probably want to reduce amount of data (GDPR) for archived identities, maybe to the very extreme (keeping only the identifier). However, this functionality may come later. |
Ideas and Questions
What about validFrom/validTo? How will this work with lifecycle states? E.g. would we automatically switch lifecycle state after validTo passes?
Suspended users:
-
How about organizational membership? It seems that we seem to need different behaviour for organization membership (assignment) and (role-like) assignments, if we want to e.g. display also inactive users in the organizational structure.
-
Could we use a concept similar to "weak construction"? I.e. if we want people to actively assigned to organizations, the assignments/inducements may have some option for that to override the lifecycles?
-
Pre-define out-of-box configuration:
-
Disable instead of delete for accounts. Maybe create a simplified "checkbox" configuration option for this, instead of writing activation expressions.
-
Delayed delete for accounts? Will we need this? Or will we handle this with lifecycle states (former→archived)? What if we need to use this feature only for some (not all) accounts?
We may still prefer immediate delete of accounts, or delayed delete with a very short interval (few days) for resources that have expensive licenses. Deleting accounts early can save us a lot of money.
Things to support when defining lifecycle states:
-
Setting whether user is considered active (enabled) or inactive (disabled) in this state. This affects
effectiveStatus. -
Setting whether to consider assignments active/inactive. Select assignments, e.g. we may want archetype assignment to be active, other assignmets inactive.
-
Removal of assignments. E.g. when entering
archivedstate. -
Change of archetype. Lifecycle state change seems to be ideal moment for automatic archetype change. We can do data minimization, which can play nice with change in archetype schema.
-
Archetype-specific display name for state? E.g.
inactiveemployee should be displayed as "Former employee", whereasinactiveproject should be displayed as "Finished project".
How can we do "onboarding only"? How to avoid deprovisioning users?
-
Bad idea: do not put users in former/archived states. This is bad, because I will not have information which users are supposed to be active. All users will look like active users to me.
-
Better idea: re-configure lifecycle former/archived lifecycle states to do nothing. I can still see whether user is active or not, but user’s account will be active. I can run a report, predicting how many accunts will be disabled before I choose to automate offboarding.
How can do offboarding only for "new" users (e.g. users that were offboarded yesterday), but leave other users unchanged? I can imagine to distinguish users based on "marks" (the marks would be set during the initial import, but not during the later synchronizations.) Is this even a reasonable thing to do?
"Categories" TODO better name
We should have some categories of information based on either importance regarding provisioning or governance/security. Or we can have both.
The categories should be distinguishable by CSS styling, e.g. colors.
Focus attributes
Some focus attributes may be more sensitive than others, e.g. GDPR and data cleanup. We should have a way how to declare them (certainly not in schema, user must be able to override) and define e.g. colors.
Example: showing former employees (even archived) with present private e-mail (extension/mail) will be indicated.
Example: data cleanup for archived people with any of the sensitive attributes present.
Resource attributes
Correlation
Attributes should be selectable as candidates for correlation before the correlation takes place.
Example: userPrincipalName and employeeNumber AD attributes are marked as correlation attributes. Maybe even with order/precedence.
Sensitivity
Some resource account attribute may be more sensitive/important than others.
E.g. if reconciliation attempts to change userPrincipalName, this is more serious than changing description.
Report should show this in red colors.
Example: reconciliation report with simulation will indicate if sensitive attribute values are being changed.
This could be even used for thresholds: if there is more than X changes of sensitive attributes, stop the task.
Missing Features
List of features missing in midPoint, and ideas for improvements.
Correlation: Candidate Identifier
Environment: Taking data from HR, correlating with AD.
There are no employee numbers in AD.
There is a username convention: jsmith, jsmith2, jsmith3
Problem: How do we correlate John Smith, Joe Smith and Jack Smith?
We cannot generate username jsmith for John, because he may in fact use jsmith2 in AD.
We cannot generate jsmith2 for Joe, as he may in fact use jsmith in AD.
This would be a mess.
Moreover, how do we set up a correlation rule? We can figure out that a "canonical" username for John Smith is jsmith, but there is nothing in midPoint users to reliably compare that with, hence no easy way to find correlation candidates.
Solution: Do not generate usernames on HR import.
Leave user’s name empty.
Instead, generate a "canonical" username (jsmith) in candidateIdentifier property.
John, Joe and Jack will all have the same value jsmith here.
When correlating users with AD, we will look for jsmith in the candidateIdentifier property, find all three candidates.
Once the account are (manually) correlated, inbound mapping from AD username to user’s name will set the correct username.
Changes in midPoint:
-
Make user
nameoptional (as a configurable option? as a default?) -
Add
candidateIdentifierto common schema. -
Figure out a way how to easily configure this. We do not want admin to set up the same expression in HR inbound mapping to
candidateIdentifier, and again doing it in AD correlator. Maybe we need some concept of "username convention" that we can refer to? Would it work, as the schemas for user and AD account are different? Maybe we can use midPoint→AD mappings to figure which attribute belongs tofamilyNameproperty? Maybe the correlator could do this. We are thinking about correlators being able to reverse the outbound mappings anyway …
Thoughts: Maybe call this cannonicalIdentifier instead of candidateIdentifier?
Probably not.
[DONE 4.7, being improved] User-friendly Resource Wizard
Environment: Configuring resource mappings (drag&drop) and correlation method.
Problem: Using the current resource wizard is too complicated. Using XML is too complex for beginners, even for simple CSV/DB table/AD resources. We can predefine some configuration (e.g. for AD), but not all, definitely not for HR resource.
Drawbacks: ?
Thoughts: TODO idea of using some functional libraries within the resource configuration may require Resource schema change.
TODO Default mapping strength? E.g. in the default AD resource or in the wizard-created HR resource?
TODO how to change the mapping strength somehow "globally" for all mappings in the resource?
Some ideas of the outbound mappings in the "wizard":
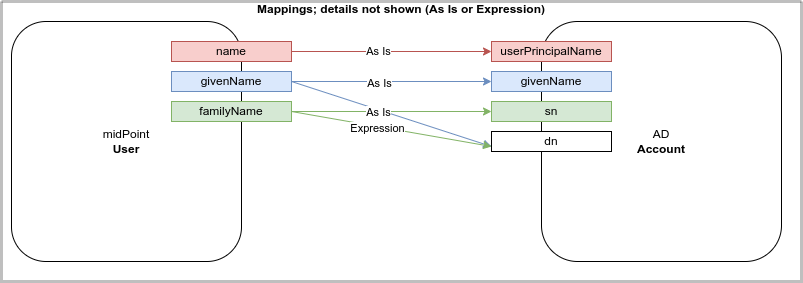
Figure 1. Resource mappings, basic view. Each property has a different color, resource attribute takes color from midPoint property in case of "as is" mappings. Mapping expressions are not expanded.
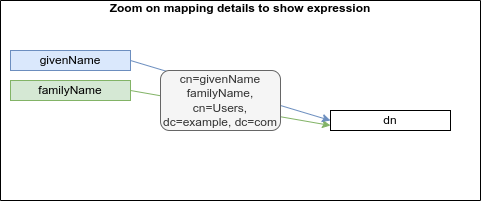
Figure 2. Resource mapping, zoomed to show expression.
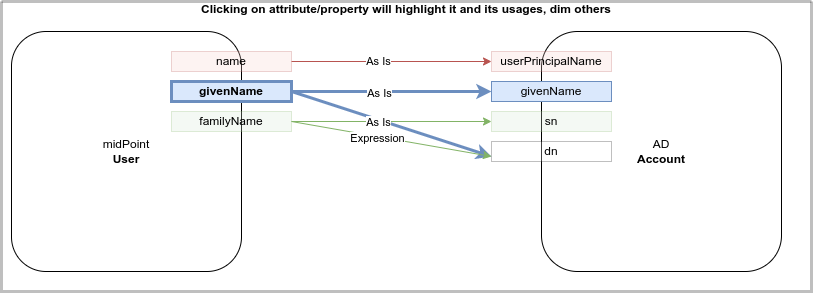
Figure 3. Resource mappings, highlighting those depending on selected property (here: givenName). All other mappings are dimmed.
[DONE, 4.7] Shadow Marks
| What about using "marks" also for other objects, e.g. focal objects in midPoint as well for marking/labelling purposes? Which parts can be recycled? |
-
Run (a simulation of) reconciliation and start shadow marking.
-
Repeat until satisfied.
We should probably have some kinds of shadow marks which specify midPoint behaviour (similar to relation kind). For example:
-
do not process at all (this could probably apply for
Protected) -
do not process automatically, only explicitly (this could probably apply for
Decommission later)
The shadow marks must be extensible with a reasonable default set in initial objects.
The shadow marks must be queryable. Perhaps even query for focal objects owning shadow with specific mark should be possible - to allow e.g. recomputation of such users. Also querying by timestamp of shadow mark should be possible. Also some metadata how/why the mark was created (by which user, by which task, case etc., and when).
Mark |
Src/Tgt System |
Typical situation |
Operations allowed |
Description |
|||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Sync |
Add |
Mod |
Del |
||||||||||
"Protected" |
Src/Tgt |
|
No |
No |
No |
No |
Protected accounts as usual. MidPoint ignores them in both synchronization and provisioning. |
||||||
"Decommission later" |
Tgt |
probably only |
No |
Yes |
Yes |
Yes |
We assume that this account should be deleted.
But not automatically.
Even when they are in situation |
||||||
"Correlate later" |
Src/Tgt |
|
No |
Yes |
Yes |
Yes |
We don’t know how to correlate this account. |
||||||
"Do not touch" |
Tgt |
any? |
No |
No |
No |
No |
Some accounts have attributes that would be overwritten or deleted by midPoint (as shown in simulations). Data does not match the policies set in midPoint. We do not want to apply them.
|
||||||
"Invalid data." Actually alias for Protected. |
Src |
|
No |
No |
No |
No |
This account has bad data. Use cases:
Could be automatically set by midPoint policies by validating the account attributes to ignore bad accounts. |
||||||
How to set shadow marks
We need to set shadow marks:
-
manually, per account
-
manually, for all accounts (in some situation). Automatically generated bulk task running on background could help
-
automatically, by policy specified in resource (legacy protected accounts definition)
-
automatically, by policy specified within the mappings
-
Example: validation of attributes
-
-
automatically, by policy, specified in shadow mark itself
-
how?
-
-
automatically, by policy specified in correlation (Katka’s idea)
-
Example: set
Correlate laterfor accounts with empty value of correlation attribute in either resource or midPoint
-
-
automatically, by policy (specified e.g. in synchronization settings)
-
Example: set
To be reviewedshadow mark + maybe even create case for allUNMATCHEDaccounts automatically. When administrator decides, he/she will set another markDo not set any other marksto prevent loops andUNMATCHEDwill behave normally (without marking and case creation).
-
Idea 1.2.2023 for future:
Combine shadow marks with cases? Some "campaign" to cleanup? Decisions will be:
-
remove mark e.g. remove
to be decommisioned,do not updateorincorrect source datato revert to midpoint standard behaviour -
change mark e.g. from
to be reviewedtoprotected -
do not decide (keep mark)
-
assign case to someone else to achieve what? Reconfiguration of midpoint?
-
change of mark or removal, e.g.
to be decommissionedmark could also go for approval/execution
The details are below:
Explicitly Marking Protected Accounts
Environment: Correlating accounts on AD (or other resource), dealing with administrator, root and similar accounts.
Problem: We would like to mark such accounts as protected. Yet, we cannot be bothered to change resource configuration.
Solution: Make a button to quickly mark an account as protected. Store that information in the shadow.
Of course, we would also need an ability to "unmark" the account, mistakes happen.
Drawbacks: Deleting all shadows would not be a "harmless" operation anymore. The information on protected accounts would disappear. However, we are already manually correlating accounts at this point. We would not delete all accounts anyway, as doing so would ruin manually-correlated links.
Thoughts: In fact, we would still configure accounts like administrator and root in resource configuration template, as these usernames are quite fixed.
However, we would need this explicit marking for other accounts, that we cannot predict beforehand.
Could we specify the protected account definition just by referring the shadow mark in the protected account query? (One query to match them all and that query could be also part of default resource configuration.)
TODO Could we allow exporting ("back up") of the shadow markings without exporting the shadow XML objects? I.e. just like we have protected accounts configured by account identifier in the resource, could we export the list of account identifiers and their markings? This could also partially mitigate the drawback above.
This may be related to MID-761
Explicitly Marking Accounts for Later Decommissioning
Environment: Correlating accounts on AD (or other resource), dealing with accounts that belong to people left the organization ages ago.
Problem: We are not entirely sure that such accounts are not needed any more. We would like to mark them, report them, discuss them on long series of meetings, bury them in soft peat for three months, get an approval, signed in triplicate, then finally disable the accounts.
Solution: Make a button to quickly mark an account for later decommissioning. Store that information in the shadow. However, do nothing else yet. Automatic behavior will be switched off. The marker could be used to report the accounts. ? Accounts marked for decommissioning will not pop out in lists of uncorrelated accounts. ? MidPoint will mostly ignore them. Until the day comes to decommission the accounts. Then we will run a pre-configured task that disables all accounts marked for decommissioning.
Manual explicit operations should still work (modify, disable, delete).
Of course, we would also need an ability to "unmark" the account, mistakes happen.
Drawbacks: Deleting all shadows would not be a "harmless" operation anymore. The information on protected accounts would disappear. However, we are already manually correlating accounts at this point. We would not delete all accounts anyway, as doing so would ruin manually-correlated links.
Thoughts: Should we still report accounts marked for decommissioning as orphaned accounts? As long as they are active, they still pose a security risk. Therefore, we should report them. However, they are "already being processed". Therefore we should not report them.
What situation should the accounts have? Really, they are not linked, unlinked or disputed. They are not really unmatched either. Maybe a new situation? Or just mind the decommissioning marker + unmatched combination? Maybe if a shadow has the decommissioning marker, then the situation does not matter anyway? (similar to protected accounts).
This may be related to MID-761
Explicitly Marking Accounts for Remediation
Environment: Correlating accounts on AD (or other resource), dealing with accounts that nobody knows about.
Problem: We are not entirely sure that such accounts are needed or not needed any more, or who they belong to. We need to work on this case, make phone calls, organize meetings and/or summon a ghost of Alan Turing to resolve the situation. This will take time.
Solution: Make a button to quickly mark an account for remediation. Maybe we can immediately open a remediation case.
Or perhaps we do not want to open the case just yet. We would like to look at all the accounts that are orphaned or cannot be correlated. Mark some of them protected, for decommissioning or remediation. Then unmark some, mark other. When we are happy, then we run a task to create all the remediation cases (which may also disable accounts marked for decommissioning).
Thoughts: We should remember the case OID in shadow, to avoid creating cases that are already created. This can also help visibility.
Maybe this is the same as "decommissioning" case, just in the decommissioning case the remediation case is "opened" and then immediately "closed" with resolution set to "disable". In fact, we do not need to create the case at all, just mark the resolution in the shadow.
There is an overlap with IGA.
Custom Activation Status Override
Environment: Source system provides user’s activation status which is stored in standard activation properties in midPoint. Administrator may need to override this information via midPoint so that user may be enabled even if he/she is indicated as disabled and vice-versa.
Problem: Sometimes the information from HR is not correct and needs to be overriden. If user’s activation/administrativeStatus is set by (strong) inbound mapping from HR, it cannot be overriden by midPoint administrator.
If a custom attribute is used, e.g. extension/customAdministrativeStatus (ActivationStatusType) is used, all outbound mappings for activation/administrativeStatus need to be modified to use the custom property instead of default activation/effectiveStatus. But this is not enough. User’s activation/effectiveStatus in midPoint is always computed from standard activation properties.
Solution: ? Maybe we need a customizable algorithm for effectiveStatus computation? This is AFAIK based on activation and lifecycleState by default.
Thoughts: I was following Custom Schema Extension - Using midPoint Types. I have updated outbound mapping like this:
<activation>
<administrativeStatus>
<outbound>
<enabled>true</enabled>
<source>
<path>extension/customAdministrativeStatus</path>
</source>
<expression>
<script>
<code>
if (!basic.isEmpty(customAdministrativeStatus)) {
return customAdministrativeStatus
}
return input
</code>
</script>
</expression>
</outbound>
</administrativeStatus>
</activation>This works, but the user in midPoint is (of course) indicated as disabled, because activation/effectiveStatus does not use the custom property and based on the documentation, effectiveStatus is not to be set explicitly.
Maybe even some reason for this - to be specified by the administrator - could be useful.
See also Value Override below.
TODO New mapping mode/strength
Environment: Mapping that would return a value, but it will not be used for provisioning, only for simulation/correlation. (TODO Mentioned above as preview or comparison) TODO Radovan
Problem: TODO Radovan
Solution: TODO Radovan
Drawbacks: TODO Radovan
Thoughts: TODO Radovan
(Not sure yet) Password Expiration
Environment: Notifying users about their password being expired soon.
| This is irrelevant (low priority) for external authentication and/or if no self-service will be used in midPoint. |
Problem: We need to notify users before their passwords are expired (password aging) as they cannot access midPoint after the password are expired.
Solution:
-
notify users in their dashboard (requires users to log in to midPoint)
-
send notification to user with soon-to-be-expired password based on the password policy that applies to them (via security policies).
-
This will require some task running periodically (each night?).
-
Or perhaps we can have trigger set in user object when user changes his/her password and then Trigger scanner can pick up this. (We already have similar solution for Unlocking users after lock-out period.)
-
TODO: what to do if security policy changes meanwhile???
-
-
Drawbacks: ?
Thoughts: Can we avoid running the task for whole population each night? Or should we allow users to log in even with expired password and change it immediately? (Maybe within some grace period.)
[DONE, 4.7] Import (single account) from resource - simulation/preview only
Environment: Importing resource object (e.g. accounts) from HR resource.
Problem: We would like to simulate/preview the import of a single account to review the configuration of inbound mappings.
Solution: Create a new action when importing resource object for simulation/preview. The output should show information if a new object in midPoint would be created or an existing would be updated (because of correlation) and how the attributes would be set in midPoint.
Drawbacks: ?
Thoughts: Would this be interesting also for bulk import with some kind of "report only"?
Show the absolute values of attributes or deltas in case the import would actually update existing user? Maybe switch between deltas/absolute?
This may be related to MID-6274
(Not sure yet) Links in Approvals Notifications
Environment: Insert link to the work item during approval notifications.
| This is irrelevant (low priority) if no approvals will be used in midPoint. |
Problem: Recipients of the approval notification need to log in to midPoint and navigate to work item - they do not have the link in e-mail notification.
Solution: Insert link to the work item to the approval notification e-mail.
Drawbacks: ?
Thoughts: This is probably related also for other notifications, e.g. other cases (Identity matching? Manual provisioning?)
[DONE, 4.6] Simple Assignment Of Archetype (Inbound)
Problem: We want to assign Person archetype to all users that are imported from HR.
In midPoint 4.4 we have to set up a non-trivial inbound mapping for that.
Even if we do, it is difficult to find all resources that are assigning Person archetype.
Solution: Make assignment of archetype a built-in feature.
E.g. objectType definition may contain reference to an archetype.
Thoughts: Maybe we may want more that an archetype? Could we assign a role or org in the same way?
Maybe we would like to have a condition when to do so?
However, maybe a condition when to use the entire objectType definition would be more appropriate?
Implementation: This was implemented in 4.6.
User-Friendly Schema Docs
Value Override
Problem: My HR system claims that my name is Jane Doe.
However, I have married few days ago, my name is Jane Doe-Smith now.
I want this name in all my systems.
If I change the name in midPoint, next recon with HR will reset it again.
-
related to MID-8802 (concept of preferred name)
Problem: My HR system claims that my work position code is X1333.
I this is a typo.
The correct value is X1334.
However, it will take at least an eternity for HR to fix their data.
I cannot wait that long with my project.
I want to fix the value manually.
However, if I change it manually, next sync with HR will reset it to incorrect value again.
Problem: My HR system claims that a person is active, because he has an active employment contract.
However, I have suspended him an hour ago, because of ongoing security incident investigation.
I want to disable this person in midPoint.
However, if I change administrativeStatus manually, the value will reset after the next recon with HR.
TODO: Solution
| Isn’t this a generalization of Custom Activation Status Override above? |
[considering DONE? - simulations, 4.7] Mapping Preview/Warnings
Problem: I’m changing a mapping in resource or role. I’m not sure what am I doing. I would like to see what is an estimated impact of the change. I would like to see:
-
(Minimal) What objects will be affected. E.g. "This mapping may affect data in accounts on
Foo Barresource", "This mapping may data inUserobjects in midPont repository, which may have effect on accounts and other objects linked to the users." -
How many objects will be affected. E.g. "This mapping may affect 42 users that have this role assigned."
-
How many objects will be affected (more details). E.g. "This mapping may affect 42 users that have this role assigned directly, and 123 users that have it assigned indirectly."
-
(Ideal) Which objects will be affected: E.g. "This mapping would affect following users: John Black, Bill White, Jack Green."
| This is actually possible via simulations already. |
Safe and Clean Removal of Resource
Problem: If I remove a resource, there are still leftovers in the repository: shadows and tasks. Especially the shadows will never get deleted, as they are practically invisible without the resource. However, first steps with midPoint may involve quiet a few create→fail→delete cycles with a resource.
Solution: Safe delete functionality for resource, that would give an option to delete shadows and tasks as well. This should also remove user links to the deleted shadows.
[DONE, 4.7] Simple Resource Wizard
Problem: The current resource wizard is pretty much useless. We need something simpler, usable for first steps.
Solution: Create wizard with just a few initial steps, just enough to connect to the resource and run connection tests. Then lead the user through configuration steps using "calls to action". This essentially changes the entire "resource details" page tests into one big wizard.
Simple Connector Management
Problem: Upgrading a connector means changing connector reference in all resources. This involves use of non-trivial wizard or even less trivial XML editing.
Solution: The usual case seems to be "I want to use latest version of a connector". Maybe we need an option for resource to look up and find the latest connector version? Maybe we need automatic procedure to upgrade the connector to the latest version, except for upgrades across major versions. We expect to have almost perfect compatibility for connector minor versions. This can be done automatically. Upgrade to a new major version may have compatibility issues, this should probably still be manual.
User-Friendly Bulk Task Generator in GUI
Problem: Administrator of midPoint has no way of creating a bulk task (e.g. for recompute, mark, user property update).
Solution: Something like "wizard", but not as technical as in Studio:
-
Click to create New bulk task
-
Select type of task (e.g. recompute)
-
Select users:
-
using Axiom query
-
using text area with list of user names (to be pasted from e.g. Excel)
-
-
Select additional info (e.g. for bulk update - which attributes should be updated, and how (expression?))
-
Show preview, which users will be modified with simulation
-
Click button to do it
Correlation-Only Mappings
Problem: Sometimes we may need inbound mappings just for the purpose of correlation; typically on target resources.
It is doable, but quite awkward (see resource-opendj-290.xml in TestFirstSteps):
<attribute>
<ref>ri:employeeNumber</ref>
<outbound>
<!-- A standard outbound mapping. -->
<strength>strong</strength>
<source>
<path>employeeNumber</path>
</source>
</outbound>
<inbound>
<!-- Inbound mapping that is here only for the sake of correlation. -->
<target>
<path>employeeNumber</path>
</target>
<!-- This is a kind of hack. We want to correlate on this attribute by a simple
mapping but do not want to use it to really modify the focus. This may happen
for correlation attributes on non-authoritative resources (e.g. target ones,
or "auxiliary" source ones). -->
<evaluationPhases>
<include>beforeCorrelation</include>
<exclude>clockwork</exclude>
</evaluationPhases>
</inbound>
</attribute>Solution: ?
Conditions for Items Correlators
Problem: When organizing items correlators into tiers, the current algorithm is such that the execution stops at a particular tier if there is a certain owner found. What is missing, though, is a "strong reject" of a match by given correlator or correlators. Consider, for example, the tiers defined as follows:
-
Matching on
employeeNumber(tier 1, confidence 1.0 - i.e., a candidate owner is automatically accepted as the definite one) -
Matching on
emailAddress(tier 2, confidence 1.0) -
Matching on
givenNameandfamilyName(tier 3, confidence 0.8 - i.e., a candidate owner(s) must be approved by the operator)
What we want to say is that if - for a given candidate - employeeNumber exists and does not match, then the match on emailAddress should not be considered;
or that it should be considered not as an authoritative one.
See e.g. resource-opendj-240.xml in TestFirstSteps.
Solution: conditions? negative confidence deltas on mismatch?
Schema Improvements
We may want to add new items to the standard schema:
-
User
-
Candidate name (candidate username): username that was generated without any iteration tokens, e.g.
jsmith. This can be very useful in correlating existing user populations. -
Date of birth, or maybe separate year of birth and birthday (they may have different data protection properties).
-
National ID number.
-
New Pre-Defined Objects
We need to add following new pre-defined objects (initial objects):
-
Personarchetype (structural) -
LDAPresource template for target (outbound provisioning)
Following objects are questionable:
-
Auxiliary person archetypes:
Employee,Contractor,Student -
ADresource template for target (outbound provisioning)
TODO For Discussion
These things need to further discussed:
-
User lifecycle/activation:
-
What about validFrom/validTo? How will this work with lifecycle states? E.g. would we automatically switch lifecycle state after validTo passes?
-
-
Correlation
-
Reversibility of outbound mappings. We have AD outbound mapping fullName → cn. We would like to use this mapping to correlate users. Could we "reverse" this mapping to do it? Probably we can, if it is
asIs. Can we do better with othe mappings? How to mark which attributes/mappings even use for correlation? Is it a good idea, anyway?
-
-
Resource definition changes
-
DONE, 4.6: Merge
synchronizationsection toobjectType -
Single-valued
objectClassinobjectType
-
-
Self service and authentication. What about self-service? When is the right time for self-service? If no roles are used (yet) in midPoint, we may need only password change; but if external authentication (e.g. AD) is used, we don’t need password change via midPoint either…
-
Credential management. When is the right time? When do we need it?
-
What about roles? We may use archetypes, of course, that is what we will recommend. However, we may need 2-5 basic roles even at this point. Will we assign all roles automatically, will admin assign them, or do we need access request process?
-
What about automatically assigned roles? How to assign them?
-
This might be related to the source system as well - for conditions
-
This requires role model to exist - at least application roles
-
-
TODO what about role requesting and approvals?
-
Even if this is done outside midPoint initially, or via manual / ticket requests, the roles are represented by group membership or something similar in the target systems
-
MidPoint should not conflict with the roles/groups assigned by other means
-
More specifically, midPoint should tolerate them
-
-
TODO multiple account intents
-
TODO related to notifications: process to warn users before their user expire (
validTo) -
Simplified resource wizard and mapping configuration
Things To Work On
These things are clear on high level, we just need to add the details, or document them:
Was this page helpful?
YES
NO
Thanks for your feedback